Read summarized version with
Large language models are great at synthesizing and less great at knowing. Ask “How did we do on revenue yesterday?” and a base LLM hits its knowledge cutoff, then confidently guesses. Retrieval Augmented Generation (RAG) fixed part of this by accessing relevant information to produce more accurate responses. Yet, baseline RAG still struggles when queries are ambiguous, multi-step, or spread across systems.
Agentic RAG closes the gap by layering AI agents on top of RAG so the system can plan, decide what to retrieve, where to retrieve it from, how to validate it, and when to try again. In short, it graduates from “search + summarize” to “reason + act.” Dedicatted’ AI engineers break it down and give hands-on advice on implementing Agentic RAG architectures.
Quick refresher: what RAG is and where it breaks
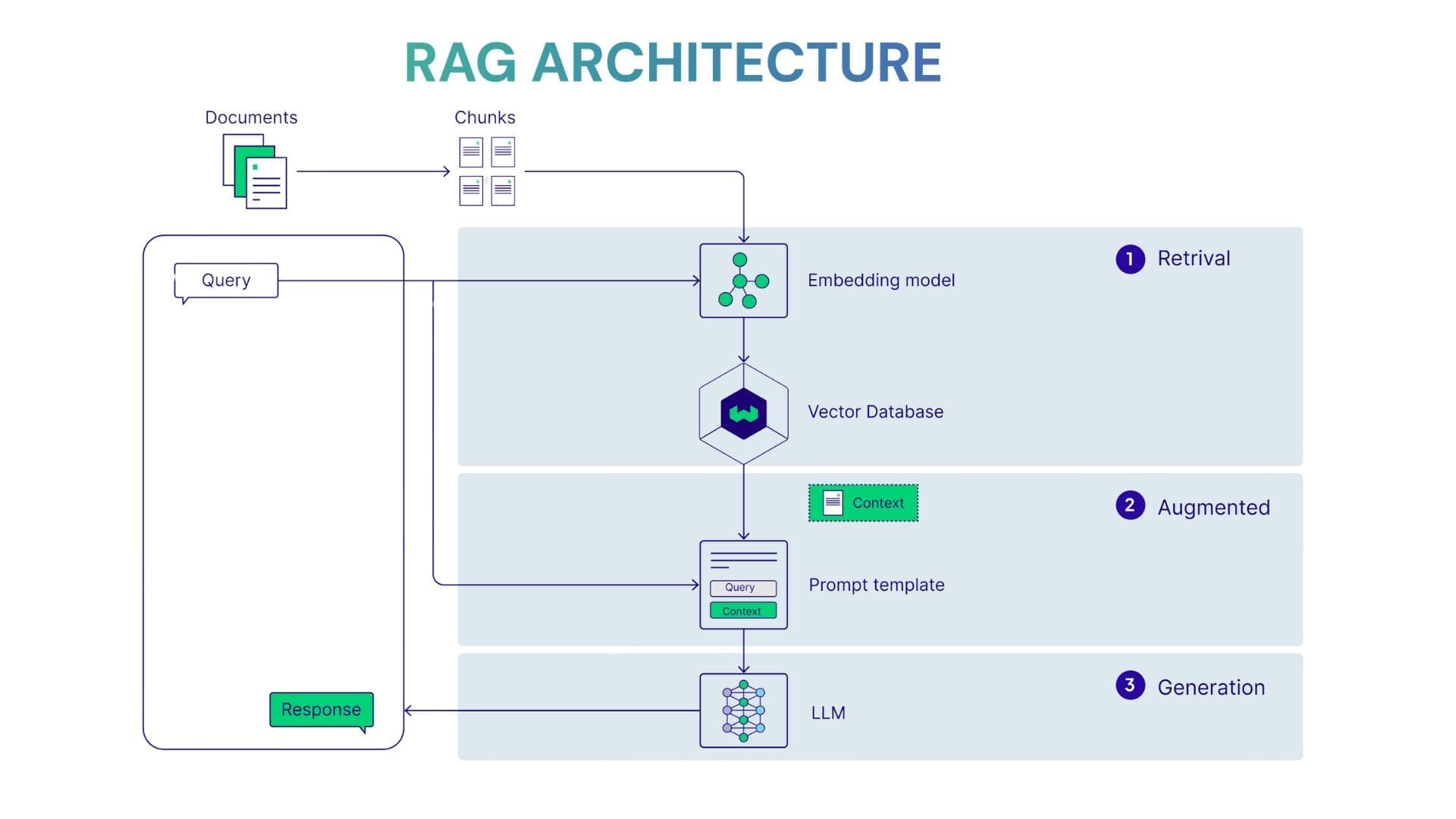
RAG is an architecture that lets a language model pull in the information it needs from external knowledge sources. Instead of answering from its own parametric memory, the model with RAG on board guides the prompt straight to the information retrieval component, or retriever. The relevant data, fetched from documents, internal company data, or specialized datasets are then passed to the generator, the second RAG component, which combines it with the model’s own memory to formulate the answer.
In the typical RAG setup for a single app, say, a customer support chatbot, you park all your info in one vector database. Both retrieval and generation operate exclusively within that repository. In such cases, where your knowledge is already under one roof, a simple retrieve-then-generate pipeline is the shortest, cheapest path to production.
What is Agentic RAG and how does it work?
When the standard retrieval framework is enriched with different types of AI agents, it takes on the shape of Agentic RAG. The agents’ memory, reasoning and planning capabilities, and context-driven decision-making elevate a RAG pipeline, so that actions and external tool calls (except those that are pre-programmed or rule-based) are guided by explicit reasoning steps.
That way, instead of simply pulling in documents and passing them to the model without much judgment, once the system is fed a query, the flow takes on several distinct turns:
1. Query pre-processing
Before retrieval, thanks to natural language processing capabilities, query planning agents, clarify vague or multi-meaning queries, expand them with synonyms, related terms, or context, segment complex queries into smaller, manageable sub-queries, and inject session or metadata context for more precise retrieval.
2. Routing and retrieval
Routing agents determine which knowledge sources and external tools (vector stores, SQL databases, calculators, APIs, web search, etc.) are used to address a user query. From here, information retrieval agents rank documents or chunks based on relevance, deduplicate and cluster similar content, and synthesize evidence across multiple sources for coherent context.
3. Multi-step reasoning over retrieved context
Reasoning agents perform higher-order operations on retrieved chunks, such as ranking, clustering, or synthesizing evidence across multiple documents rather than passing raw context directly to the model. It reduces noise and contradictions, so generated answers are better grounded and easier to trust.
4. Validation and control
Validation agents apply consistency checks, source verification, confidence scoring, or other evaluation mechanisms to filter and refine retrieved context before it informs generation. This lowers the risk of hallucinations and reinforces factual correctness in the generated output.
5. Orchestration of output generation
To ensure that the final response is not just a raw aggregation of retrieved content but a cohesive, context-aware answer that leverages multiple sources while minimizing contradictions or hallucinations, agents guide how the LLM produces the final output, structure answers (summaries, step-by-step, bullet points), select which evidence to emphasize, and trigger follow-up retrieval if gaps are detected.
So, with RAG agents folded into retrieval and generation processes, the constraints we talked about earlier lose much of their grip.
Agentic RAG architecture
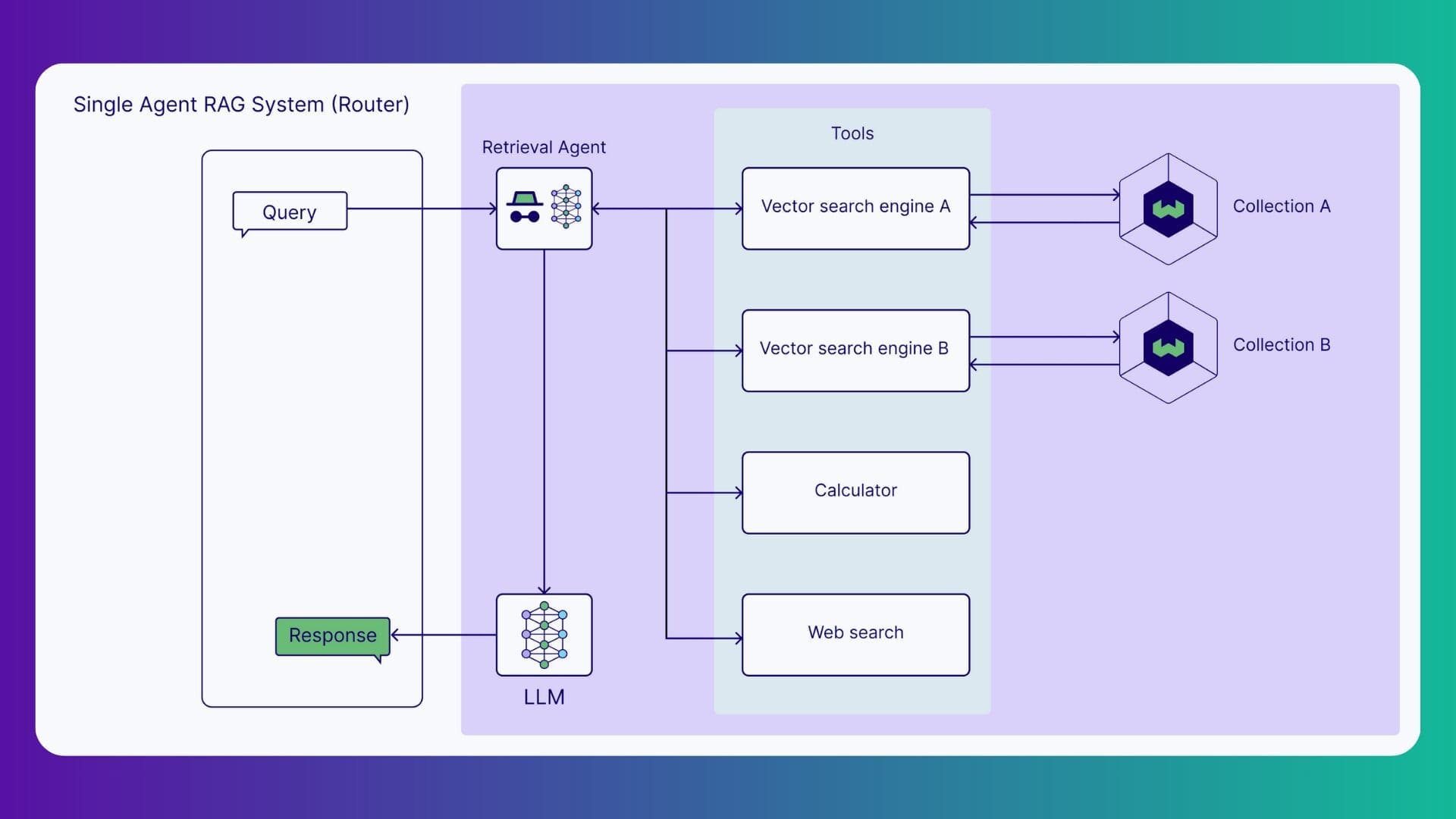
It’s worth noting that the division of labor across intelligent agents is an architectural choice. Some Agentic RAG setups rely on a single agent that plans, retrieves, reasons, and validates in sequence. This is called a single-agent RAG system. It keeps the pipeline simple and easier to maintain, though it lacks the modularity and parallelism of multi-agent systems, those with a team of specialized agents, each dedicated to a particular function in the pipeline. It’s usually a task complexity that dictates the breadth of agent involvement.
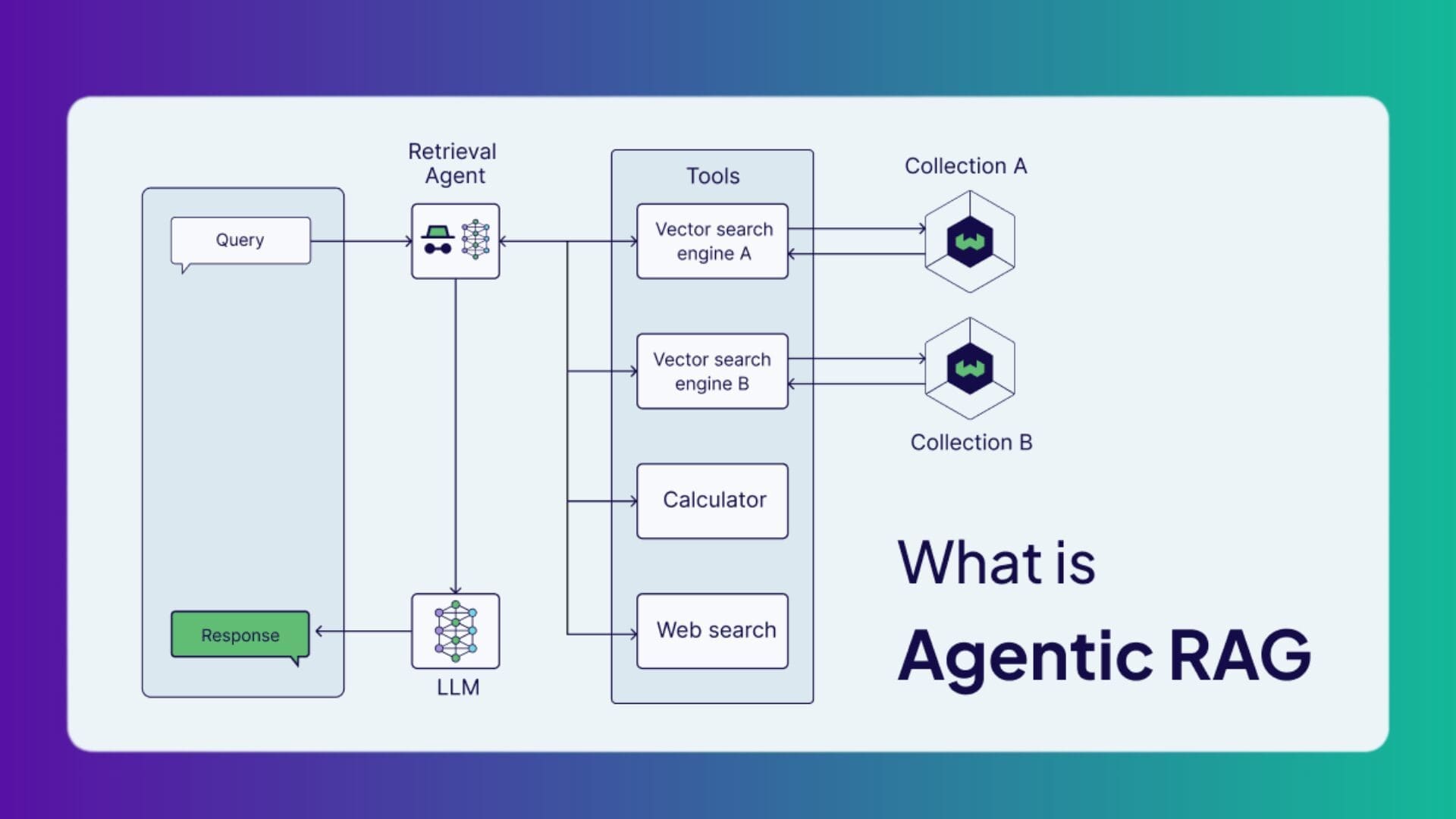
For example, in customer support, for FAQs like “How do I reset my password if I’ve lost access to my email?” which can be answered straight from one knowledge base, a single-agent setup does the job just fine. But once a request gets messy, touches multiple systems, or has more than one ask, like: “I was double charged for my subscription last month, and I also need to update my billing address. Can you fix this and tell me when my refund will arrive?” – that’s where you need more than one brain at work. A multi-agent setup can split the load, tackle each piece, and give the customer a cleaner, more accurate answer.
What Agentic RAG brings to the enterprise table
The ultimate payoff of agentic RAG is response accuracy so high it raises the ceiling for enterprise AI, moving from surface-level questions to nuanced, high-stakes queries. This goes beyond what traditional RAG or RAG-free LLMs can deliver. It comes from agentic-powered iterative, self-directed retrieval, on-the-fly fusion of structured data and unstructured text, autonomous tool usage, and built-in verification.
Besides, agentic RAG is easy to scale. Without overhauling the infrastructure, agents can be brought in for tougher, more complex work requiring extra parallelism or specialized skills and pulled back when tasks lighten. Building on the customer support example we mentioned above: suppose the current multi-agent RAG system has two agents – one handling FAQs (password resets, account setup) and the other managing billing issues (simple refunds, payment verification).
Now, the company launches a loyalty program. Customers soon start asking questions like “How do I redeem my points?” or “Can I combine coupons with loyalty rewards?” This is where a specialized agent can be added quickly, thanks to the system’s modular design.
Each additional agent increases token usage and tool calls. Costs will scale roughly linearly and you’ll eventually run into context-window limits. So it’s ‘easy to scale’ operationally (compute can expand), but not costless or limitless.
Where Agentic RAG is already paying off
Customer support automation
Agentic RAG is arguably the real breakthrough in hyper-personalized customer support. While reading a client’s intent, mood, and the context behind their issue, agents simultaneously pull in every record from the CRM and unstructured data like emails, PDFs, etc. to build a complete picture of the customer. This context-rich background allows them to craft responses that don’t just tick off a request, but wow the client with the level of service and lock in their loyalty.
Employee support optimization
To level up IT support, enterprises plug a RAG helper into the helpdesk so tickets get answered quicker and employees can get back to work. As soon as IT support bot hears “VPN drops every afternoon,” it decides whether to pull VPN logs, DHCP lease tables, or the user’s laptop event history, then pre-assembles a ticket with the likeliest fix and any sibling issues.
Clinical decision support systems
Retrieval agents help healthcare professionals synthesize vast amounts of medical information, research papers, patient records, and drug databases, to produce more reliable, context-aware recommendations when needed. Simple LLM searches or traditional RAG would struggle with multi-step reasoning, cross-referencing symptoms, treatments, and contraindications.
Legal research support
With Agentic RAG, days-long legal drudge-work shrinks into a ten-minute chat. The agentic-powered LLM dives through statutes, rulings, and filings, surfaces the cases that matter, maps how they hang together, and hands the lawyer a ready-made argument trail.
Investment analysis
Multiple agents pull Form 10-K, the latest Fed minutes, and internal risk models, cross-check trends, and synthesize a one-page brief explaining why spreads are widening. Analysts skim, click “agree,” and move on.

Pro tips from the field for implementing an Agentic RAG system (so you don’t learn the hard way)
To lock in better results from your LLM-based enterprise solutions, consider these field-tested guidelines for building Agentic RAG architectures. The key challenge of any RAG implementation is ensuring a robust data pipeline and secure data storage. Always ensure that databases are protected and access to them is tightly controlled.
- No matter how solid your agentic RAG setup is, hallucinations can still pop up. Agents can step on each other’s toes and compete for resources, and the more of them you throw in, the harder it is to keep things running cleanly. As a rule of thumb, keep the agent team as lean as possible for the task at hand.
- Take the time to provide agents with a full picture of each tool’s capabilities. Explain how it works and what it’s best suited for, enabling agents to choose the right tool for the job.
- Regularly review a subset of agent decisions to ensure reasoning aligns with expected business logic. If the agent’s confidence in a tool choice or document relevance is low, trigger either a human-in-the-loop review or fallback logic.
- Remember GIGO: if external data don’t provide clear, detailed context, even the smartest agent will churn out poor results. To enhance response accuracy, look after your data quality and make sure your knowledge base documents pack enough relevant context, so agents pull the accurate information instead of garbage.
- With more autonomy comes the need for oversight. Set up detailed logging, monitoring, and alerting in your RAG model so you can track agent actions, detect issues, and continuously improve system performance.
Where to take it next
Agentic RAG can already push quality and speed up a noticeable notch, but it still slams into the same ceiling every enterprise AI hits: garbage data, brittle tools, compliance walls, and cost caps. Our team can map an Agentic RAG architecture to your stack (connectors, security, KPIs) and prototype a path to production in weeks, not quarters.


