Read summarized version with
Working time:
2023 – ongoing
Industry:
High Tech
The service:
Data Architecture
Overview
The client is a prominent technology company based in Southern Europe, specializing in advanced analytics and consumer insights powered by artificial intelligence (AI). Established to transform consumer reviews and feedback into actionable business intelligence, the company operates across multiple continents including Europe, North America, and Asia. Their innovative platform provides comprehensive and real-time insights, significantly impacting product development, marketing strategies, and overall business performance for leading brands across diverse sectors.
Their services encompass sophisticated data analysis solutions that convert vast amounts of customer-generated content into meaningful market intelligence. Leveraging cutting-edge machine learning algorithms, the client’s platform helps businesses quickly interpret complex consumer behaviors, preferences, and evolving market trends.
Having experienced considerable growth, the company now collaborates with major global brands, further establishing its reputation in the analytics industry. A recent significant growth equity investment underscores their ambitious plans for continued expansion and technological advancement.
Want to get your copy of case study?
Download it here.
By submitting this form, you agree with our Terms & Conditions and Privacy Policy.
Challenge
As the client rapidly expanded their customer base and entered new markets, the volume and complexity of the data they managed grew exponentially. This rapid growth highlighted critical weaknesses within their existing data architecture, limiting their ability to efficiently scale and adapt to market demands. Specific challenges included:
Fragmented Data Ecosystem
The client faced multiple duplicated datasets across various storage solutions, making it difficult to maintain data accuracy and consistency. This increased the complexity and cost of data governance and storage.
Inefficient Compute Resource Management
The client experienced frequent issues with over-provisioned and poorly optimized computational resources. High operational expenses incurred from maintaining these resources did not translate into proportional analytical improvements, significantly straining their financial resources and affecting overall profitability.
Limited Data Search and Retrieval Capabilities
The absence of a scalable and robust search infrastructure led to significant bottlenecks in data analysis workflows, causing delays in critical processes. This limitation reduced business agility and responsiveness, hindering the company’s ability to quickly adapt to market changes and opportunities.
Extensive Manual Data Processing
The client heavily relied on manual data cleaning, normalization, and migration processes. Skilled analysts and engineers were burdened by these repetitive tasks, diverting their valuable time and expertise away from strategic and innovative projects. Consequently, this negatively impacted productivity and slowed down overall business growth.
Solution
To address the challenges and streamline the client’s data architecture, our team devised and executed a comprehensive, technically robust approach, which incorporated several strategic initiatives:
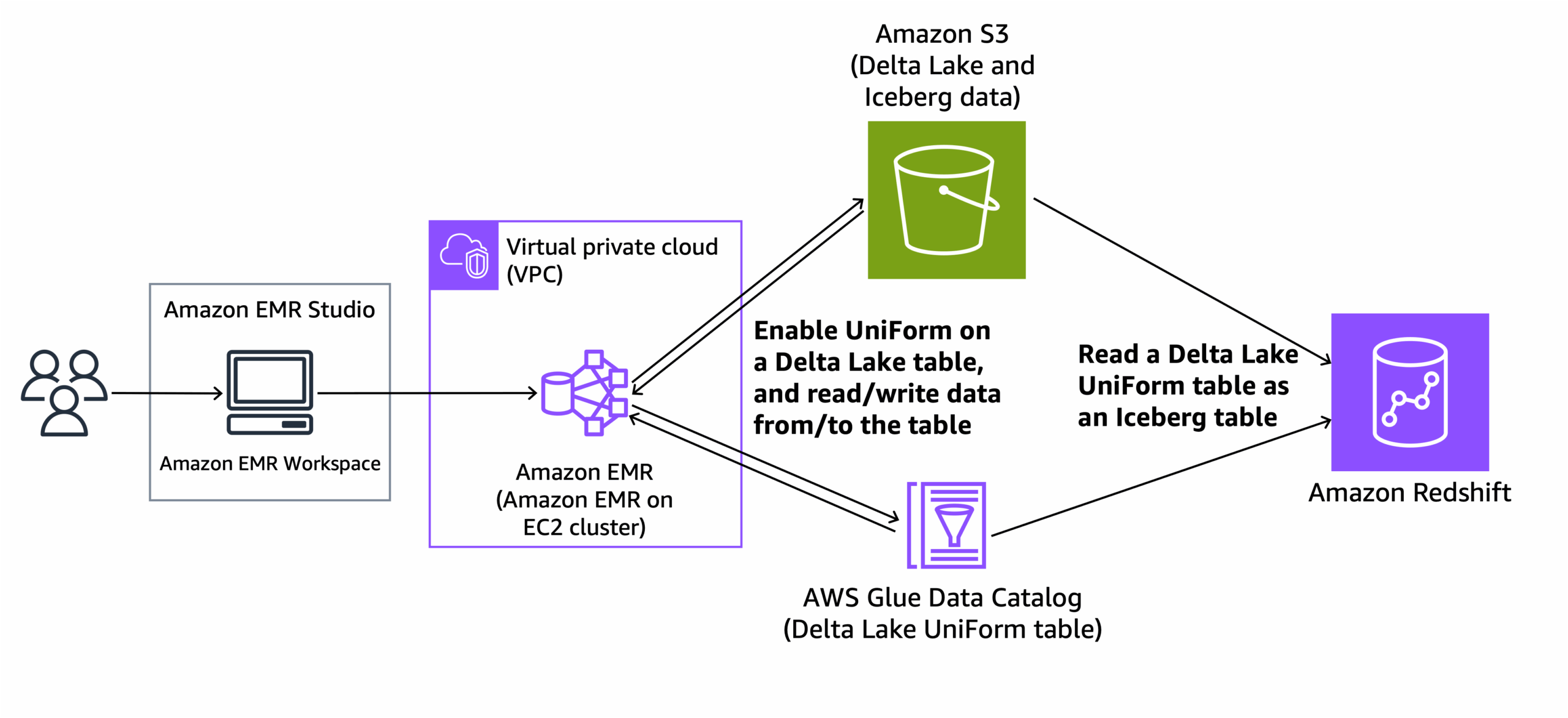
1. Adoption of DeltaLake (Apache Iceberg)
We implemented DeltaLake using Apache Iceberg to drastically reduce data duplication by shifting from storing entire data snapshots to capturing only incremental changes. This approach significantly minimized storage requirements and enhanced data consistency and accuracy across multiple datasets.
2. Dynamic Spark Clusters on Kubernetes
To improve computational efficiency and optimize resource utilization, we established dynamic Spark clusters orchestrated via Kubernetes. This strategy allowed for real-time scaling of compute resources, leveraging cost-effective spot instances. As a result, the client experienced substantial cost savings while maintaining optimal performance for intensive data computations.
3. Migration to AWS OpenSearch
We replaced the existing data search infrastructure with AWS OpenSearch to significantly enhance data retrieval and analytics capabilities. AWS OpenSearch provided robust, scalable, and real-time search functionalities, effectively eliminating bottlenecks and enabling quicker, more efficient data-driven decision-making.
4. Creation of Robust Data Pipelines
We developed automated data pipelines to streamline data movement, cleansing, and normalization processes. These pipelines reduced manual workload and allowed the client’s skilled analysts and engineers to focus on high-value strategic tasks, accelerating the pace of innovation and enhancing overall productivity.
Intelligent Data Lifecycle Management
A standout feature of this project was the implementation of sophisticated data lifecycle rules, designed explicitly to optimize storage efficiency and significantly reduce operational expenditures. By carefully defining and automating these lifecycle policies, we ensured that data was stored precisely where it offered maximum value at minimum cost.
These customized rules dynamically transitioned data between storage tiers based on access frequency and business relevance. Frequently accessed data remained instantly available, while older or less critical data seamlessly moved to cost-effective, long-term storage solutions. This strategy greatly minimized unnecessary expenses related to data storage, aligning storage costs directly with the value extracted from the data.
For the business, this meant more predictable budgeting, reduced infrastructure costs, and enhanced clarity regarding their data assets. Ultimately, the intelligent lifecycle management empowered the client to focus financial resources more strategically, directly supporting their business objectives and growth.
If you find this case interesting, we recommend taking a closer look at
Results
The comprehensive overhaul of the data architecture delivered tangible and remarkable outcomes for the client, directly addressing their earlier inefficiencies and driving substantial business benefits. These measurable improvements have had a lasting impact, creating a solid foundation for future growth and scalability.
1. Significant Storage Cost Reduction
The implementation of sophisticated data lifecycle management rules dramatically optimized storage usage. By moving to incremental change-set storage with DeltaLake (Apache Iceberg) and automating transitions between storage tiers, the client successfully achieved an 80% reduction in data storage costs. This significant decrease allowed the business to allocate funds previously spent on storage to innovation and strategic initiatives, further accelerating company growth and profitability.
2. Optimized Compute Resource Utilization
Establishing dynamic Spark clusters on Kubernetes and strategically leveraging spot instances significantly enhanced compute efficiency. This initiative resulted in a remarkable 50% reduction in compute resource costs, freeing up substantial budgetary resources for reinvestment in innovation and growth. The client now benefits from flexible, scalable compute resources that adapt to workload demands, effectively eliminating resource wastage.
3. Enhanced Data Search Efficiency
Migrating to AWS OpenSearch greatly improved the client’s data retrieval capabilities, tripling data search speeds. This substantial acceleration enabled the business to perform real-time analyses and swiftly respond to evolving market demands and opportunities. Employees across various departments now enjoy quicker, more efficient access to critical insights, significantly improving productivity and enabling more informed decision-making processes.
4. Fully Automated Data Processes
Automated data pipelines replaced previously manual, labor-intensive tasks of data movement, adjustment, and cleaning. The new pipelines operate continuously, delivering rapid, error-free data processing 24/7. This automation allowed the client’s data teams to focus exclusively on strategic and innovative projects, significantly boosting overall productivity and operational agility. Moreover, the automation substantially reduced human error, increased data reliability, and provided enhanced consistency across all datasets.
Collectively, these results positioned the client to sustain and scale their operations efficiently, fostering continued competitive advantage and supporting ongoing business expansion. The improvements delivered not only addressed immediate operational inefficiencies but also strategically positioned the company to tackle future challenges and seize emerging market opportunities confidently.


