Read summarized version with
Amazon Web Services’ annual tech conference AWS re:Invent has wrapped. And the singular message, amid a deluge of product news and keynotes, was AI for the enterprise.
This year it was all about upgrades that give customers greater control to customize AI agents, including one that AWS claims can learn from you and then work independently for days. Amazon CTO Dr. Werner Vogels capped off the final night with a keynote aimed at lifting up developers and assuaging any fears that AI is coming for engineering jobs.
AWS re:Invent 2025, which runs through December 5, started with a keynote from AWS CEO Matt Garman, who leaned into the idea that AI agents can unlock the “true value” of AI.
The next day, Swami Sivasubramanian, AWS VP of Agentic AI, doubled down on this narrative. His message was: we’re entering a new era where natural language is all you need to describe an outcome – and agents simply build the solution.
While AI agents were the headline story, AWS delivered a wave of additional announcements throughout the week. Here’s a concise recap of the highlights.
AI & ML: The New Agentic Era at AWS
AWS just redrew the AI landscape – again. What used to be “models and assistants” has evolved into a fully-fledged ecosystem of autonomous agents, custom silicon, and enterprise-ready AI infrastructure. This year’s announcements weren’t incremental, they marked a turning point.
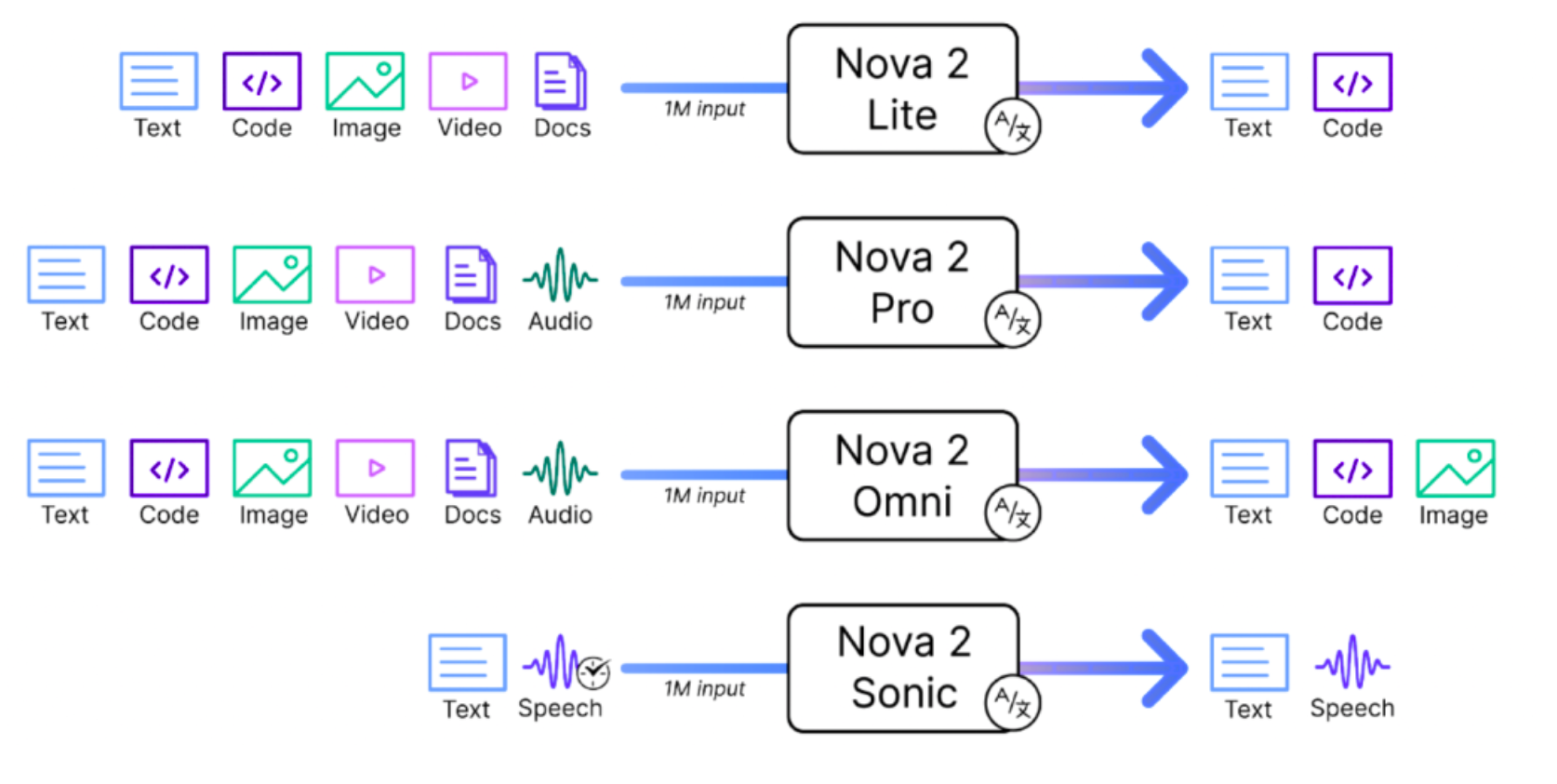
Amazon Nova 2: The Agent-Ready Model Family
AWS expanded its flagship Nova model suite with four powerful additions, each engineered for real-world production use.
- Nova 2 Sonic – Human-Level Voice Interactions: Speech-to-speech conversations with multilingual support, natural prosody, and contextual memory. Ideal for customer service, live assistance, and global voice experiences.
- Nova 2 Lite – Fast, Efficient, and Scalable: Optimized for cost and speed, with a huge context window for long documents, logs, or multi-hour conversations. Designed for workloads where latency and cost per token matter.
- Nova 2 Omni – Multimodal Intelligence in One Model . Accepts text, images, video, and audio as input and outputs text or images. One model, many modalities , removing the need for separate pipelines.
- Nova Act – The Breakthrough: Autonomous Browser Automation . It is an AI agent built for web workflow automation and it’s now GA. (Surpassed 90% automation reliability in testing. Hertz achieved 5× faster development cycles using Nova Act in production)
Pricing remains the standout factor. Nova 2.0 Pro is listed at 1.25 dollars per million input tokens and 10 dollars for output. According to Artificial Analysis, a benchmark run cost about 662 dollars with Nova 2.0 Pro, compared to 817 dollars for Claude 4.5 Sonnet and 1,201 dollars for Google Gemini 3 Pro.
Beyond Nova Act, AWS is also introducing three frontier agents designed to work as persistent teammates across the software lifecycle.
Kiro acts as a virtual developer that keeps long term project context, proposes changes across repositories and picks up engineering tasks like bug triage and code cleanup inside tools such as GitHub and Jira. Early users say it automates 20-30% of routine dev work.
The AWS Security Agent focuses on secure design and implementation. It scans code, reviews architecture documents and can run targeted penetration style checks, then suggests fixes so security review becomes continuous rather than a late stage gate.
The AWS DevOps Agent targets incidents and operations, tying into observability tools and CI or CD systems to help isolate root causes, propose remediation steps and automate routine runbook work. Already being tested by Commonwealth Bank of Australia and Western Governors University. Together, the three agents embody Amazon’s “agents are the new cloud” narrative.
Nova Forge: Custom Frontier Models Without Starting From Scratch
With Nova Forge, Amazon is trying to move beyond shallow fine tuning and into shared frontier training. Organizations get access to pre trained, mid trained and post trained checkpoints, then mix in proprietary data at each stage. Those custom systems are called “Novellas“ – private frontier models that keep Nova’s general reasoning while absorbing domain specific knowledge, policies and tone. Early users include Booking.com, Sony, Reddit and several financial and life sciences firms.
Forge also adds reinforcement learning “gyms” where models practice inside simulated environments, plus tools for distilling smaller, faster variants and a safety toolkit for guardrails and policy enforcement.
Otherwise, your investment will have been all for naught. On this journey, executives run into large, complex challenges that require enterprise-wide alignment. These highly interconnected focus areas are make or break when it comes to scaling agentic AI.
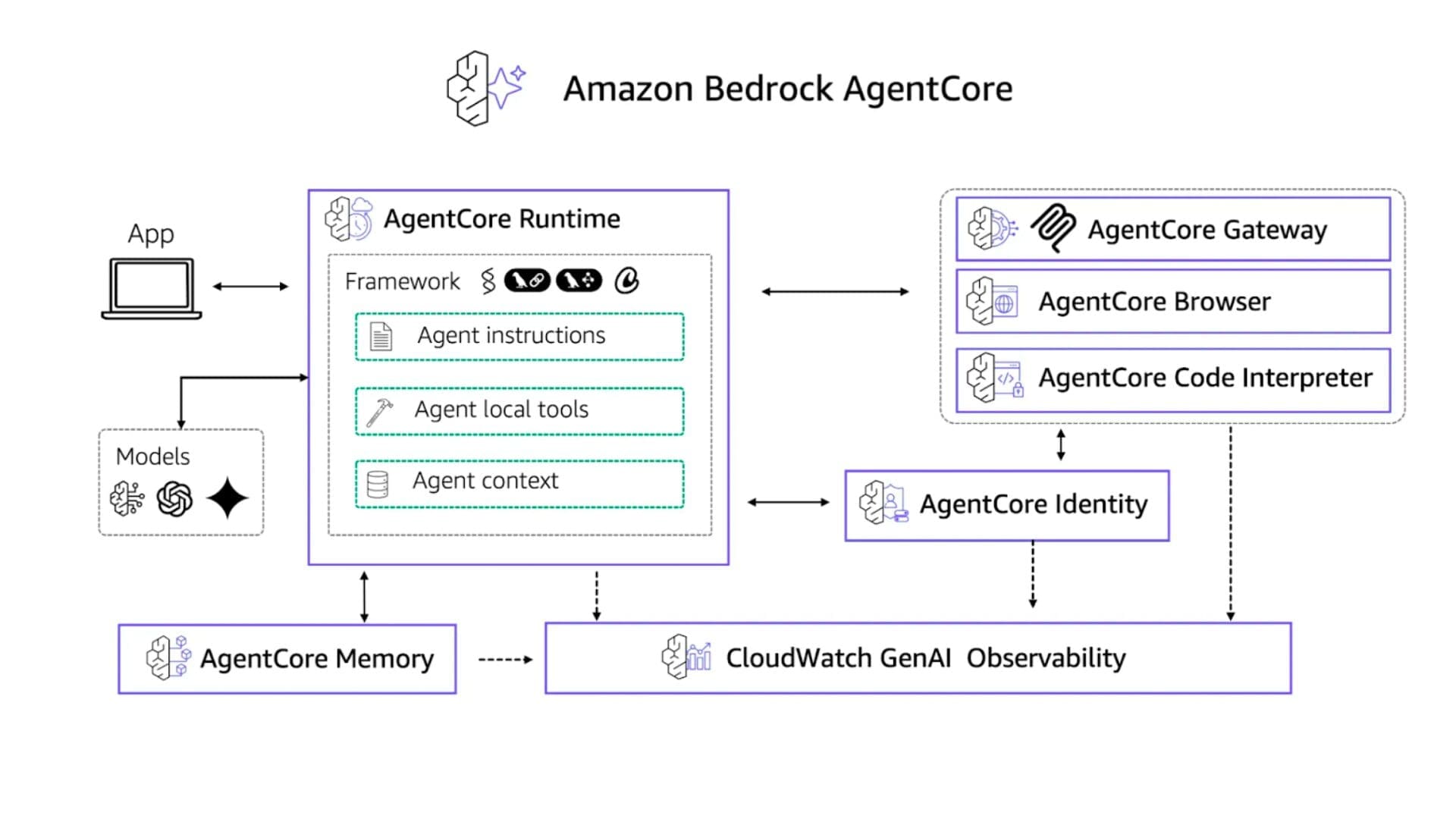
Bedrock AgentCore: Production-Ready Autonomous Systems
Amazon Bedrock AgentCore is an agentic platform to build, deploy, and operate highly capable agents securely at scale . As part of Amazon Bedrock, AWS’s fully managed service for building and scaling generative AI applications without managing infrastructure, Agent Core extends these capabilities to agentic systems.
While experimentation and proofs of concept are valuable, they only deliver real business impact once agents are operational in production. It is this transition into production that introduces significant hurdles, including security, scalability, interoperability across heterogeneous agents, handling large payloads, and supporting long-running processes. Agent Core directly addresses these challenges by providing an enterprise-grade environment that unifies runtime execution, communication, state management, identity, and observability. It is framework- and model-agnostic, allowing organizations to use their preferred tools such as CrewAI, Strands, or LangGraph, and foundation models ranging from open source to providers like OpenAI, Google Gemini, or Anthropic (even those not available in Amazon Bedrock’s base model API).
AWS strengthened Bedrock’s agent framework with several enterprise must-haves:
- Policy Engine (Preview): Natural language rules that constrain agent behavior (“never delete customer data”).
- Evaluations: 13 built-in quality and safety monitors.
- Memory: Persistent learning from past interactions.
Companies like MongoDB, Swisscom, and the PGA Tour are already scaling agents with these tools.
Accelerated ML Development
MLflow Integration with SageMaker in serverless mode means data scientists can track experiments and manage models with zero setup, seamlessly alongside SageMaker’s pipelines.
HyperPod Checkpoint-Free Training enables elastic training on distributed clusters. Large model training jobs can recover from hardware failures in minutes without manual checkpoints and auto-scale across thousands of accelerators, boosting utilization and cutting training costs by up to 40%.
Compute & Infrastructure: The Silicon Advantage
Amazon is stepping deeper into custom silicon with the debut of its Graviton5-powered EC2 M9g instances, a major architectural leap that could reshape how enterprises run large-scale cloud workloads. Performance gains are meaningful: up to 25% higher compute versus the previous generation, powered by 192 CPU cores and a 5x larger L3 cache.
With Graviton now responsible for more than half of all new CPU capacity added to AWS for three consecutive years, adoption is becoming widespread. Ninety-eight percent of the top 1,000 EC2 customers, including Airbnb, Adobe, Atlassian, Epic Games, Formula 1, Pinterest, SAP, Siemens, Snowflake, and Synopsysare already benefiting from Graviton’s price-performance profile. The architecture also incorporates faster memory speeds, higher bandwidth on both networking and storage, and improved energy efficiency, offering a very compelling mix of performance scaling and lower infrastructure cost.
Trainium3 UltraServers
AWS introduced a new version of its AI training chip called Trainium3 along with an AI system called UltraServer that runs it. The TL;DR: This upgraded chip comes with some impressive specs.
It’s got 4x more performance over Trainium2, which is fantastic. It’s also going to be 40% more performance per watt, which is obviously very, very important as we think about how much compute we can get out of every watt of power that we put into the device. And that makes it about 40% better energy efficient as well when we go from Trainium2. We’ve also increased the memory bandwidth by 50%.
AWS also announced it is actively developing Trainium4, designed to bring performance improvements including at least six times the processing performance in FP4 precision, three times the FP8 performance and four times more memory bandwidth
AWS Lambda Managed Instances: Serverless Flexibility Meets EC2 Cost Models
Under the hood, AWS Lambda Managed Instances utilize capacity providers to organize EC2 instances based on specific compute characteristics such as instance type and scaling parameters, configured via the Lambda console or IaC tools. With this setup, efficient resource utilization is ensured by routing requests to pre-provisioned execution environments, thereby minimizing cold starts and enabling multiconcurrency. Moreover, during traffic spikes, AWS automatically scales by launching new instances. At the same time, built-in safeguards prevent resources from being overwhelmed, maintaining a serverless operational model with no manual configuration or instance management.
AWS AI Factories – On-Premises, Fully Managed AI Clouds
Amazon Web Services (AWS) is introducing its own on-premises AI factory, bringing cloud innovation and control directly into customer facilities and reshaping how organizations run AI alongside their ERP systems.
The new AWS AI factories, announced at the 2025 AWS re:Invent, install Nvidia GPUs, AWS Trainium chips, high-speed networking, storage, and security into customers’ existing data centers. The factories also are wrapped with managed services like Amazon Bedrock and SageMaker so organizations can develop and deploy AI applications at scale without building their own GPU data center from scratch.
AWS described the offering as a dedicated AI infrastructure that “operates like a private AWS Region” inside the customer facility, giving low-latency access to compute, storage, and AI services while helping meet security, sovereignty, and regulatory requirements. Saudi Arabia’s HUMAIN initiative, for instance, is deploying an AI Zone with 150,000 AI chips using this model.
For ERP-heavy organizations in regulated sectors, AWS AI factories effectively move the AI development and inference plant into the same physical footprint as the ERP core. Sensitive data can stay in existing data centers and jurisdictions, while AI workloads still use AWS services and Nvidia’s full-stack software without bespoke integration of GPUs, storage, and networking. Per Network World, the factories combine the on-premises control of AWS Outposts with the broader service catalog of AWS Local Zones, promising both low-latency access to ERP data and a wider palette of AI and agentic services.
That positions AWS as one of several competing “factory as a service” providers, but with the benefit of its two decades of cloud operations and native integration into the broader AWS ecosystem.
Data & Analytics: Cheaper, Faster, More Collaborative
AWS continues to push the boundaries of cost efficiency, data privacy, and performance across its cloud stack. One of the most exciting updates is the expansion of Clean Rooms ML, which now allows multiple organizations to collaborate on machine learning using privacy-preserving synthetic datasets – a huge win for teams operating in regulated environments.
Cost savings also took center stage with the introduction of Database Savings Plans, offering up to 35% reductions across services like RDS and DynamoDB, already proving valuable for companies such as Vanguard and SmugMug. RDS itself received major upgrades, including support for up to 256 TiB of storage, CPU optimizations that can cut licensing costs by more than half, and the addition of a free SQL Server Developer Edition for development and testing.
Even deployment workflows get smoother thanks to a new one-click Vercel integration. On the search and analytics front, OpenSearch now delivers a significant GPU-powered boost, enabling vector search performance up to ten times faster at a fraction of the previous cost. Altogether, it’s a strong wave of updates focused on flexibility, performance, and real-world savings.
- With over 10 years of experience in the tech industry, Dedicatted has delivered 20+ successful data science and AI projects. We have a team of skilled AI developers, who are well-versed in various verticals to help you identify where it can drive the greatest value: whether it’s accelerating research, automating operations, or optimizing decision-making.
- We adhere strictly to security protocols and regulatory frameworks, including ISO 27001:2013, PCI DSS, ISO 9001:2015, and GDPR, to guarantee the protection and integrity of data.
Whether you want to experiment with Nova agents, optimize infrastructure with Graviton or Trainium, or build a secure agent platform with Bedrock – we’ll help you make the right moves, fast. Let’s explore how AWS’s new AI ecosystem can accelerate your roadmap.
Book a consultation with Dedicatted and start building the next phase of your business today.



