Read summarized version with
Every July, a familiar ritual plays out across retail operations teams. War rooms fill up. Engineers go on-call. Someone quietly refreshes the latency dashboard every ninety seconds. Slack channels that are normally quiet at 3 AM light up with incident threads. Amazon Prime Day 2026 was no different , except the numbers got bigger. Hundreds of millions of transactions compressed into 48 hours. Traffic spikes that make Black Friday look like a Tuesday. Customers arriving simultaneously from mobile apps, social commerce feeds, voice assistants, in-store kiosks, and the web.Some brands processed every order without a single incident page. Others didn’t survive the first wave.
Whether the commerce system had been designed to absorb demand spikes by scaling the right layer independently, or whether it was still running on a monolithic foundation that treats the entire stack as one unit. This article explains what headless commerce architecture is, why it performs where traditional systems fail, how AWS services form the infrastructure backbone, and what a practical migration path looks like for teams that are still on legacy platforms and have the next peak event already on the calendar.
Why Legacy Commerce Architecture Fails at Scale
What makes today’s fraud environment categorically different isn’t just the technology – it’s the economics. For most of financial crime’s history, sophisticated fraud was expensive to execute. It required skilled operatives, significant preparation time, and manual effort that naturally limited scale. AI has dissolved all three constraints simultaneously. The same machine learning tools, the same large language models, the same automation capabilities available to your technology team are available to the people targeting your institution, often deployed faster, with fewer governance hurdles, and at a fraction of the cost. The result is fraud that is highly personalized, adaptive, and cross-channel by design. Four threat vectors are hitting Canadian banks hardest right now
Traditional eCommerce platforms: Oracle ATG, IBM WebSphere, Magento, Demandware were built in the 1990s and early 2000s for a specific context: desktop web browsers, predictable traffic, and a single selling channel. They solved that problem well. The architecture made sense for what it was designed to do.
The design was monolithic by nature. The frontend templates, the checkout engine, the product catalog, the order management logic, the tax calculation, the promotion rules – all of it lived in the same tightly coupled system, deployed together, scaled together, and maintained together. Change one layer, and you risk breaking another. Update the checkout flow, and you might inadvertently affect how promotional discounts calculate. Patch a security vulnerability in the product search service, and you need a full platform deployment.
That coupling created a compounding maintenance burden over time. Every new feature required understanding the entire system. Every deployment required regression testing across the full stack. Every scaling decision required provisioning infrastructure for everything, even when only one service was under load.
What Happens Under Traffic Spikes
When Prime Day traffic arrives, the bottleneck in a monolithic system is almost never the commerce logic. The product catalog does not suddenly become computationally expensive. The order management system does not struggle with a price lookup. The bottleneck is the presentation layer: the rendering, the session management, the API calls that populate the page the customer is looking at.
In a monolithic architecture, you cannot scale the presentation layer independently. To handle more storefront requests, you scale the entire application, including the checkout engine, the catalog service, the promotion engine, all of it: even though only the frontend is under pressure. That is expensive, slow, and often insufficient, because the system was not designed to be distributed in the first place.
The failure modes are predictable and well-documented. Timeouts on the storefront cascade into checkout failures. Session state becomes inconsistent across instances. The database, which was designed for a single-instance deployment, becomes the global bottleneck. Teams spend the peak event managing the architecture instead of watching the revenue.
The Channel Fragmentation Problem
Beyond peak performance, there is a structural problem that accumulates over years rather than hours. Traditional eCommerce platforms were built for one channel: the desktop web. Every assumption in the architecture: the template system, the session model, the rendering pipeline was built around that single surface.
As the number of customer touchpoints expanded, most organizations handled it by building separate systems for each new channel. A mobile app got its own backend. An in-store POS system ran on a different commerce engine. A marketplace integration became a separate data feed. Each channel had its own pricing logic, its own inventory view, its own promotion rules. None of them talked to each other reliably.
The result is what the industry calls a scattered IT landscape: inconsistencies in product data, pricing, and inventory across channels; high total cost of ownership from distinct licensing fees and integration costs; and an IT team that spends more time synchronizing systems than building new capabilities. Gartner’s data on this is unambiguous. Organizations that have adopted a composable architecture: the broader pattern that headless commerce belongs to outpace competitors by 80% in the speed of new feature implementation. That gap does not come from working harder. It comes from removing the architectural dependencies that slow every deployment down.
47% of consumers now expect a webpage to load in two seconds or less. Our own research found that a single second of improvement in page load time corresponds to a 2% increase in conversions: a number that, at Prime Day scale, represents millions of dollars per hour. A website that performs adequately on a normal Tuesday will fail these expectations under peak load, and customers who encounter a slow or broken experience during a high-intent shopping event do not wait for the page to load. They leave.
Beyond performance, 73% of consumers now use multiple channels along their shopping journey. They research on mobile, compare on desktop, purchase through a social commerce integration, and return in-store. Each of those touchpoints needs to present consistent pricing, accurate inventory, and seamless cart state. A scattered IT landscape cannot deliver that. A unified commerce backend exposed through APIs can.
What Headless Commerce Actually Is
The definition is precise: headless commerce separates the frontend presentation layer (the “head”) from the backend commerce engine. The frontend is what customers see and interact with the storefront, the product pages, the checkout flow, the account dashboard. The backend is what handles the business logic: product catalog management, pricing and promotions, cart and checkout processing, order management, inventory, customer profiles, and payment workflows.In a traditional monolithic system, these two layers are tightly coupled. They share a database. They are deployed together. The frontend templates are hardcoded to expect specific data structures from the backend. They cannot evolve independently.
In a headless architecture, the frontend and backend communicate exclusively through APIs, typically REST APIs or GraphQL. The backend does not know or care what the frontend looks like. The frontend does not care how the backend stores or processes data. Each side can be updated, replaced, or scaled without the other.
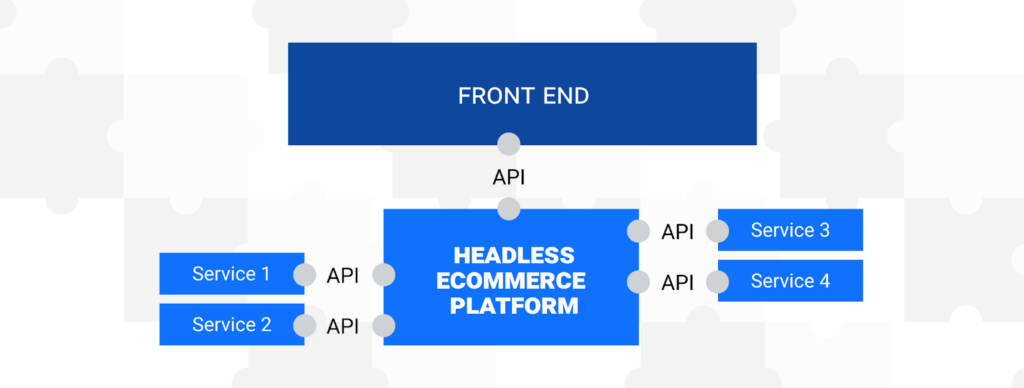
What This Means in Practice
The practical consequences of that separation are significant and immediate.
A single backend powers every channel simultaneously. The same product catalog, pricing engine, and order management system that serves the web storefront also serves the mobile app, the in-store POS terminal, the voice assistant integration, and any future channel. A product update made once propagates everywhere in near-real time. A promotion configured once applies across all surfaces. The inventory view is consistent regardless of where the customer is looking.
Frontend and backend teams work independently. Marketing and digital experience teams can redesign the storefront, launch campaign landing pages, run A/B tests, and ship UX improvements without waiting for backend deployments. Backend engineers can update business logic, migrate infrastructure, or integrate a new payment provider without coordinating a frontend release. Each team moves at its own pace.
Updates propagate in near-real time. In a traditional commerce architecture, changes to the frontend interface can take minutes or hours to reflect. In a headless architecture, because the frontend fetches data from the backend through APIs at request time, updates are reflected immediately. During a flash sale, a price change or an inventory update is live the moment it is made in the backend.
The technology stack is no longer fixed. Because the frontend and backend communicate through a standard API layer, each side can be built with the best available technology for its purpose. The frontend might be built in Next.js or React. The backend might be a custom microservices implementation. The two can evolve independently as technology improves and requirements change.
Headless, MACH, and Composable: Understanding the Terminology
These three terms are often used interchangeably and they are related but distinct. Understanding the differences matters for having precise internal conversations about architecture strategy.
Headless commerce is specifically about the decoupling of the frontend from the backend. It is a design pattern, not a platform or a product. MACH architecture is the broader framework: Microservices-based, API-first, Cloud-native, and Headless. It describes the full set of principles that modern commerce systems should be built on, of which headless is one pillar. Composable commerce is the strategic approach that MACH enables: the ability to assemble a commerce platform from best-of-breed services rather than purchasing a monolithic all-in-one solution. Instead of one platform that handles everything (CMS, search, checkout, loyalty, personalization), you choose the best tool for each function and compose them through APIs.
The MACH Pillars in Detail
Microservices: Independence at the Function Level
Microservices architecture decomposes a complex application into small, independently deployable services, each responsible for a specific business function. In a commerce context, this means separate services for the product catalog, cart management, checkout, order management, pricing and promotions, loyalty, tax calculation, inventory, and customer profiles.
Each service is self-contained. It has its own data store, its own deployment pipeline, and its own scaling parameters. It communicates with other services through well-defined APIs. It can be updated without requiring changes to any other service. It can be scaled independently based on actual load, if checkout is under pressure during a peak event, only the checkout service needs additional capacity. The operational benefits compound over time. A bug in the promotions engine does not take down checkout. A deployment of the loyalty service does not require a maintenance window for the catalog. A new integration with a third-party tax provider affects only the tax service. Teams can own individual services without needing to understand the entire system.
API-First: The Integration Foundation
API-first means that every capability in the commerce platform is exposed through a well-defined, consistently designed API interface before any frontend is built. The API is the product. Everything else: the storefront, the mobile app, the internal tools, the integrations consumes it.
This is how brands add best-of-breed components to their commerce stack. A new personalization engine integrates through the same API layer as everything else. A new payment provider adds a new endpoint without disrupting existing ones. A new channel: TikTok Shop, a connected TV experience, an enterprise B2B portal is built on top of existing APIs without requiring backend changes. GraphQL has become the preferred API pattern for modern headless commerce because it allows the frontend to request exactly the data it needs no more, no less. Unlike REST APIs that return fixed data structures, GraphQL queries are defined by the consumer. A mobile app that only needs a product name, image, and price does not receive the full product data object. This reduces payload size, improves performance, and makes the frontend faster.
Cloud-Native: Infrastructure That Matches Demand
Cloud-native means that the application is designed from the ground up to run on cloud infrastructure: not lifted and shifted from an on-premise data center, but built to take advantage of elastic compute, managed services, global distribution, and pay-as-you-go pricing. The contrast with legacy infrastructure is stark. Traditional commerce platforms that run on on-premise infrastructure or hybrid cloud deployments require teams to provision for anticipated peak load. The standard practice was to estimate peak traffic, multiply by a safety factor, and deploy hardware accordingly. That hardware sits idle for the 340+ days per year that are not peak events, representing sunk capital cost that earns no return.
Cloud-native infrastructure, particularly on AWS, eliminates this model. AWS Auto Scaling monitors application performance continuously and adds or removes capacity in real time as demand changes. A commerce platform running on AWS handles a 10x traffic spike without a pre-planned infrastructure expansion. When the spike subsides, capacity scales back down and the cost returns to baseline. The bill reflects what was actually consumed.
This model also shifts expenses from capital expenditures to operational expenditures: from buying infrastructure to consuming it as a utility. Like electricity or water, you pay for what you use. For a retailer that runs a major promotion once a year, this is the difference between financing a data center that is only needed for 48 hours and paying for those 48 hours of compute at the moment they are needed.
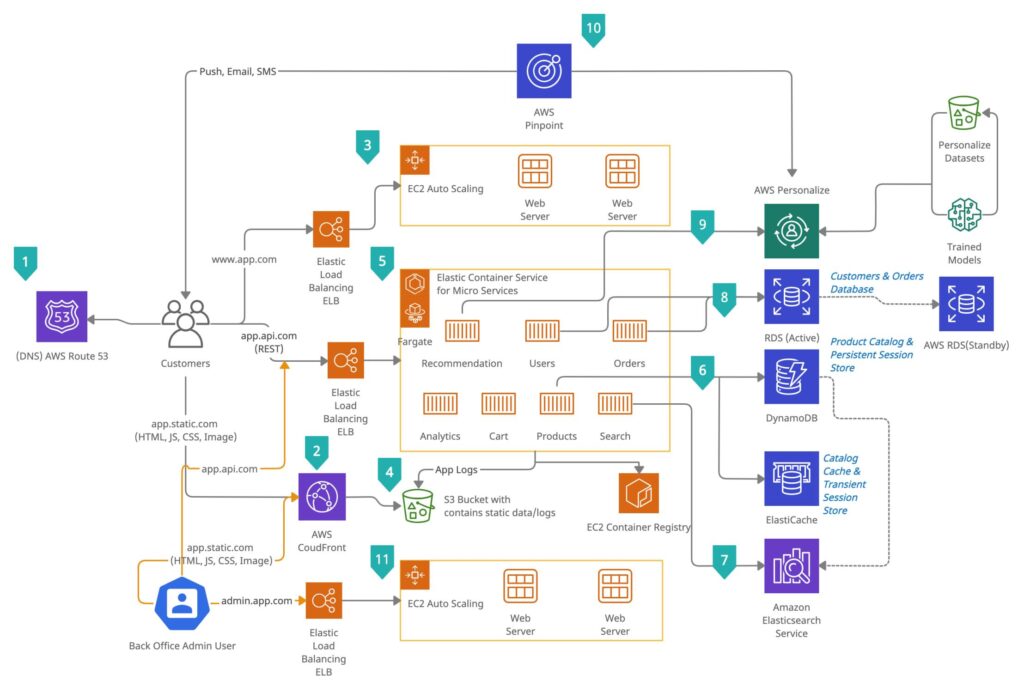
AWS Infrastructure for Production-Grade Headless Commerce
Lambda is the serverless compute layer that powers custom business logic without the overhead of managing servers. In a headless commerce architecture, Lambda functions handle the logic that sits between the frontend and the commerce engine: tax rule enforcement, fraud signal scoring, loyalty point calculations, custom pricing logic, webhook handlers, and API extension endpoints.
Lambda scales from zero to thousands of concurrent executions within seconds. When a Prime Day flash sale triggers a surge of cart additions, Lambda functions handle the spike automatically and cost nothing when the traffic subsides. Integration with API extensions means Lambda can inject custom logic synchronously into commerce operations: for example, preventing an order from exceeding a custom quantity limit, or validating a promotion code against a third-party loyalty system before allowing checkout to proceed.
Practical implementation: Use Lambda for all synchronous API extensions that need to run inside the commerce transaction, and for asynchronous event handlers triggered by Amazon EventBridge. Keep each function focused on a single responsibility. Set appropriate concurrency limits to protect downstream services during unexpected spikes.
Amazon EventBridge is the serverless event bus that enables event-driven architecture across the commerce stack. When something happens in the commerce platform – an order is placed, a product sells out, a cart is abandoned, a customer signs up : EventBridge routes that event to every downstream system that needs to respond.
This replaces the nightly batch synchronization jobs that make legacy integrations feel sluggish. Inventory updates flow to warehouse management systems in real time. Order events trigger fulfillment workflows immediately. Cart abandonment events reach marketing automation platforms within seconds, enabling re-engagement messages while the customer is still in a decision-making window.
Practical implementation: Map your commerce events (order created, inventory updated, price changed, customer registered) to EventBridge rules during the integration design phase. Use EventBridge’s content-based filtering to route events only to the services that need them. Design downstream consumers to be idempotent capable of handling the same event more than once without producing incorrect results.
Amazon DynamoDB is the managed NoSQL database service that provides the scalability and schema flexibility that modern product catalogs require. Unlike relational databases that enforce rigid schemas, DynamoDB’s schemaless model allows product attributes to vary by product type without schema migrations. A clothing product has size and color attributes; an electronic has voltage and compatibility attributes. Both live in the same database without structural conflicts.
DynamoDB’s performance characteristics are designed for the kind of read-heavy workload that a product catalog generates. It handles millions of requests per second with single-digit millisecond latency, scales horizontally without downtime, and replicates globally across AWS regions for low-latency access from anywhere in the world.
Practical implementation: Design your DynamoDB access patterns before designing the data model. The primary keys and global secondary indexes that support your most frequent queries determine the performance characteristics. For product catalog use cases, model around how the frontend will query, typically by product ID, category, and search facets, rather than around how the data is organized internally.
Amazon ECS is the runtime layer for containerized microservices. Each microservice in the commerce architecture: catalog, pricing, checkout, order management, loyalty runs in its own container, deployed and scaled independently through ECS. It integrates with AWS Fargate for serverless container execution, eliminating the need to manage the underlying EC2 instances. Teams define the CPU and memory requirements for each service and Fargate handles the infrastructure. Combined with Application Auto Scaling, ECS automatically adjusts the number of running containers based on CPU utilization, request rate, or custom CloudWatch metrics.
Practical implementation: Define separate ECS services for each microservice, with independent scaling policies calibrated to that service’s specific load characteristics. Use ECS service discovery for internal service-to-service communication. Implement health checks at both the container level and the load balancer level to ensure that unhealthy instances are replaced automatically without manual intervention.
Amazon Personalize is AWS’s managed machine learning service for real-time product recommendations and personalized user experiences. It ingests interaction data: product views, cart additions, purchases, search queries and produces recommendation models that update continuously as new data arrives.
In a headless commerce architecture, Personalize connects to the backend through API calls from Lambda functions, with recommendation results surfaced through the same API layer that serves all other frontend components. During Prime Day, personalized recommendations are the mechanism that converts browsing into purchasing, showing the right product to the right customer at the moment of highest intent.
Practical implementation: Start with an interaction dataset built from historical event data before launching the recommendation engine. Define your use case (frequently bought together, customers also viewed, personalized ranking) before selecting the Personalize recipe. Subscribe to real-time event tracking through Amazon EventBridge so that interaction data flows into Personalize models continuously rather than in scheduled batch updates.
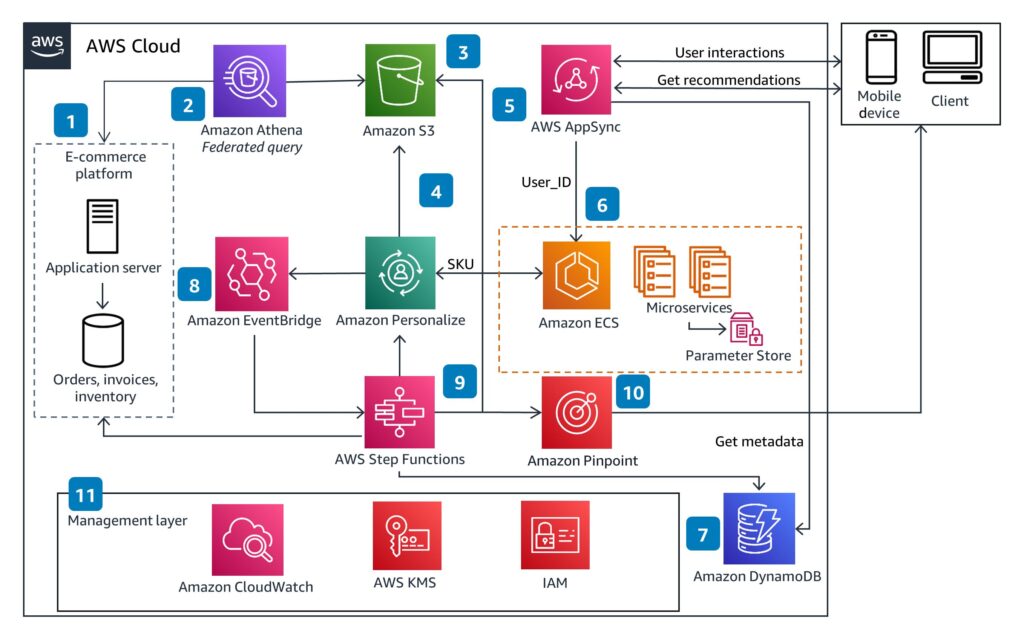
Amazon Pinpoint is the customer engagement platform that handles marketing communications across email, SMS, push notifications, and in-app messaging. In an event-driven headless commerce architecture, Pinpoint sits downstream of EventBridge, receiving commerce events and triggering engagement campaigns based on customer behavior.
A cart abandonment event from the commerce platform hits EventBridge, routes to a Lambda function that evaluates the customer’s eligibility for a re-engagement message, and triggers a Pinpoint campaign that delivers a personalized email within minutes of the abandonment. A flash sale launch event triggers a push notification to all customers who have opted into the mobile app. A back-in-stock event triggers an SMS to customers on the waitlist.
Practical implementation: Design your Pinpoint segments around commerce events rather than demographic attributes. A segment defined as “customers who viewed this product category in the last 7 days and have not purchased” is more actionable for a Prime Day campaign than a demographic segment. Use Pinpoint journey workflows to sequence multi-step engagement flows — view → abandon → remind → convert — rather than single-message campaigns.
Architecture Patterns for Different Scales
Pattern 1: Headless Storefront on Existing Backend (Starting Point)
The minimum viable headless architecture decouples only the frontend, while leaving the existing commerce backend in place. A new storefront is built in Next.js or React, consuming the existing platform’s APIs. The customer experience is rebuilt from scratch with full frontend freedom, while backend migration is deferred. This pattern is appropriate for organizations that need immediate frontend flexibility: faster campaign deployments, performance improvements, new channel support , but are not ready for a full backend migration. It delivers value quickly and creates the decoupling that makes subsequent backend migration lower-risk.
AWS services involved: CloudFront for global delivery, Amplify for frontend hosting and CI/CD, Lambda for any custom frontend middleware, WAF for edge security.
Timeline: 8–16 weeks for a production-ready storefront, depending on the complexity of the existing backend’s API surface.
Limitations: The existing backend still constrains scalability and flexibility. Backend deployments still affect the full platform. The Strangler Pattern migration should begin in parallel.
Pattern 2: Full MACH Stack on AWS
The architecture integrates EventBridge for event-driven downstream processing, Lambda for custom business logic injected through API extensions, DynamoDB for high-performance catalog caching, CloudFront for global storefront delivery, Personalize for real-time recommendations, and Pinpoint for customer engagement.
AWS services involved: Full stack as described before. EventBridge, Lambda, DynamoDB, CloudFront, ECS, Personalize, Pinpoint, Connect, Amplify, Cognito.
Timeline: 6–12 months for a full migration using the Strangler Pattern, depending on the number of integrations and complexity of the existing data model.
What it enables: Independent scaling of every service during peak events. Frontend deployments in minutes rather than hours. New channel support without backend changes. Real-time inventory and pricing across all surfaces.
Pattern 3: Composable Commerce with Best-of-Breed Stack
The most advanced implementation treats every commerce capability as an independently selectable service. The commerce backend handles transactions. A headless CMS (Contentful, Sanity) handles content. An AI-powered search and discovery layer (Algolia, Constructor) handles product discovery. A personalization engine (Dynamic Yield, Amazon Personalize) handles recommendations. A loyalty platform handles rewards. Each connects through the API layer.
This is the architecture that brands like Sephora, Audi, and Volkswagen Group run in production. It requires the highest level of engineering investment but delivers the highest level of flexibility: any component can be replaced without disrupting the others.
AWS services involved: Full stack, plus integration patterns for each third-party service through EventBridge and the API layer.
Timeline: 12–18 months for a full composable implementation. Typically phased: commerce backend first, then best-of-breed integrations, then advanced personalization and AI layers.
When Headless Is the Right Choice and When It Is Not
Headless architecture delivers its clearest value in specific conditions. Before committing to the investment, validate that these conditions apply.Strong case for headless:
- You serve customers across three or more channels (web, mobile, in-store, marketplace) and need consistent data across all of them
- You have annual peak events (Prime Day, Black Friday, product drops, seasonal campaigns) where traffic spikes 5x or more above baseline
- Your marketing or digital experience team is blocked by developer dependencies for routine frontend changes — campaign landing pages, content updates, UX iterations
- You are planning to launch in new markets or on new channels within the next 18 months
- Your current platform’s licensing or customization costs are growing faster than revenue
- You need to integrate best-of-breed services (search, personalization, loyalty, payments) that your current platform does not support natively
Weaker case for headless:
- You operate a single-channel DTC store with stable traffic and no imminent expansion plans
- Your team lacks experience with modern frontend frameworks and API-driven development
- You are in early stage and need to move fast with a simple platform: the additional engineering overhead of headless would slow you down more than it enables
- Your current platform meets all requirements and has headroom for the next 2–3 years of growth
The honest framing is this: headless is not the right architecture for every organization at every stage. It is the right architecture for organizations that are growing, expanding to new channels, and expect their digital presence to evolve significantly. The investment in architectural flexibility pays off over a 3–5 year time horizon. Organizations looking for a quick win in the next quarter should consider whether the returns justify the upfront cost.
The Total Cost of Ownership Comparison
The upfront cost of a headless migration is higher than staying on a legacy platform. Implementation timelines are longer. Engineering requirements are higher. The skill set needed to operate the platform is more advanced. The long-term total cost of ownership typically reverses that comparison within 12–18 months of launch, driven by:
- Elimination of per-channel commerce licenses replaced by a single composable backend
- Reduction in integration maintenance costs as API-first connections replace custom point-to-point integrations
- Faster time-to-market for new features reducing the engineering cost per feature over time
- Infrastructure cost reductions from elastic cloud replacing over-provisioned on-premise or hybrid infrastructure
- Reduction in peak-event incident costs: engineering time, potential revenue loss from downtime, which are invisible in a TCO comparison until they happen
How Dedicatted Approaches Headless Commerce on AWS
Dedicatted is a Toronto-based AWS Premier Tier Services Partner and top 2% global AWS partner, holding AWS GenAI Competency, MSP designation, and AWS Agentic AI Pilot status. Our approach to headless commerce engagements starts where it should: with a business-first audit, not a technology selection.
What our engagement process looks like:
Assessment phase: We evaluate your current commerce architecture against your growth objectives, channel strategy, and peak performance requirements. We identify the specific failure modes, whether they are frontend scalability issues, backend coupling, channel fragmentation, or integration debt and quantify the business impact of each.
Architecture design: We design the target state architecture with AWS services and commerce platform selection calibrated to your specific requirements. We do not prescribe a one-size-fits-all stack. A mid-market DTC brand has different requirements than a multi-brand enterprise or a B2B distributor.
Migration roadmap: We build the Strangler Pattern migration roadmap with milestone definitions, risk mitigation plans, and business continuity controls. Every migration milestone is designed to deliver value before the next one begins.
Implementation: Our delivery teams execute the migration with dedicated solution architects, AWS-certified engineers, and commerce platform specialists. We own the architecture decisions and deliver the outcome.
Ongoing operations: Post-launch, our MSP practice provides continuous cloud optimization, security management, and platform evolution as your requirements change.
If you are planning for the next peak event and your current architecture is a concern, the right time to start the conversation is now. The Strangler Pattern gives you a path that does not require shutting down the revenue engine to modernize it. But it requires time that the proximity of the next peak will eventually eliminate. Let`s talk
Frequently Asked Questions
How long does a headless commerce migration typically take? A phased migration using the Strangler Pattern typically runs 6–12 months for a full backend migration, depending on the number of integrations, the complexity of the existing data model, and the team’s current technical capability. A frontend-only decoupling, standing up a headless storefront on top of an existing backend can be completed in 8–16 weeks.
Does headless commerce improve SEO? Yes, when implemented correctly. Modern frontend frameworks like Next.js support server-side rendering (SSR) and static site generation (SSG), which ensure that search engines can crawl and index content properly. Sites built with these frameworks and deployed on edge networks through CloudFront consistently outperform traditional platforms on Core Web Vitals, which directly influence search rankings.
Can headless commerce handle B2B as well as B2C? Yes. A MACH-based commerce backend supports B2C, B2B, B2B2C, and direct-to-consumer business models through the same API layer. B2B-specific features: custom pricing per customer, tiered discounts, purchase order workflows, account-level credit limits are implemented through API extensions and custom data models without requiring separate platforms.
What is the difference between headless and composable commerce? Headless refers specifically to the decoupling of the frontend from the backend. Composable commerce is the broader strategy of assembling a commerce platform from best-of-breed independent services: commerce engine, CMS, search, personalization, loyalty, payments each selected for its specific capability and integrated through a common API layer. Headless architecture is a prerequisite for composable commerce.
How does headless commerce handle peak traffic like Prime Day? In a headless architecture on AWS, peak traffic is handled through independent scaling of each layer. The frontend, served through CloudFront’s edge network, absorbs traffic globally without touching origin infrastructure. AWS Auto Scaling adds backend service capacity automatically as load increases. Lambda functions scale to thousands of concurrent executions within seconds. The result is that peak events scale with demand rather than requiring pre-provisioned capacity.


