Read summarized version with
More than 70% of organizations are already experimenting with or investing in generative AI, yet most enterprise AI projects still struggle to move beyond the pilot stage. The challenge is rarely the model itself. It is the complexity of turning prototypes into secure, scalable, production-ready systems without driving up infrastructure costs or operational overhead.
That is where Amazon Bedrock comes in. Built by Amazon Web Services, Amazon Bedrock gives organizations access to leading foundation models through a fully managed service, helping teams accelerate development while maintaining security, governance, and scalability. Combined with AgentCore, AWS also enables businesses to build and orchestrate agentic AI workflows without stitching together an entire ecosystem from scratch.
This article explores how Amazon Bedrock works, its key capabilities and enterprise use cases, and what organizations should consider when building and scaling generative AI solutions on AWS.
What Amazon Bedrock actually is
Amazon Bedrock is a managed service from AWS that gives you access to foundation models from multiple providers through a single API. That includes Anthropic Claude, Meta Llama, Mistral, Amazon Nova and Titan, AI21 Jamba, Cohere, DeepSeek, and others. You can use them out of the box, customize them with your own data, and ship applications without managing the infrastructure underneath.
The pitch is simple. Instead of stitching together a model provider, a vector database, an orchestration layer, a security layer, and a deployment pipeline, you get one platform that handles most of it for you. Your team focuses on the use case. AWS handles the rest.
With Amazon Bedrock, Dedicatted can provide clients with a cost-effective service to help examine large volumes of data to customise models and utilise natural language for various use
What Bedrock gives you
- Choice of models: A growing catalogue of foundation models from leading providers, all behind one API. Switch between them without rewriting your application.
- Customization without exposure: Fine-tune or use retrieval-augmented generation (RAG) on your proprietary data without sending it outside your AWS environment.
- Serverless infrastructure: No clusters to provision. Bedrock scales with demand and bills based on what you actually use.
- Knowledge Bases: A managed RAG service that connects models to your documents, websites, or databases without writing your own retrieval pipeline.
- Guardrails: Configurable safety controls for content filtering, topic blocking, and personally identifiable information (PII) redaction.
- A Playground for non-developers: Marketing, product, and operations teams can experiment with models in a graphical interface before engineering writes a line of code.
Why Foundation Models Matter
A foundation model is a large, general-purpose model trained on enormous datasets. The point is reuse. The same model can write a customer email, summarise a 40-page report, draft SQL, or extract entities from a contract, with no task-specific training. That changes the economics. Instead of building and training a separate model for each use case, your team adapts one model to many.
This is why Bedrock matters. It puts a catalogue of these models behind a single, governed API, so you can pick the right one for each task. Use a small, cheap model for classification and routing. Use a larger model for reasoning and code. Switch between them as the work demands.
How Bedrock works in practice
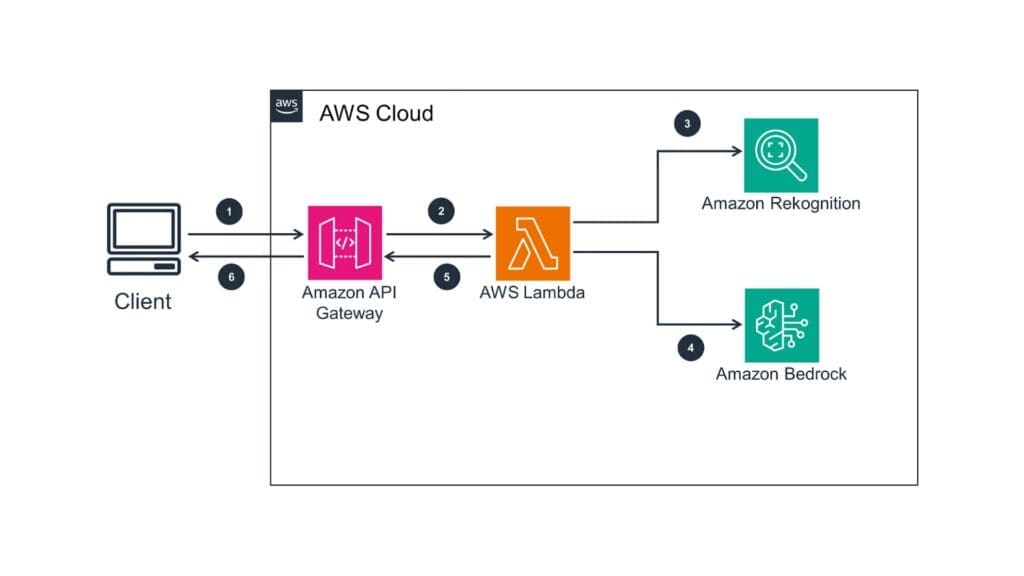
There are three steps from idea to working application.
- Bedrock offers models for text, image, and multimodal tasks. Anthropic Claude for reasoning and conversational depth. Amazon Nova or Mistral for cost-efficient text generation. Stability AI for image creation. Llama for open-weight flexibility. The right choice depends on the workload, the budget, and the data residency requirements.
- Amazon Titan: Use for text tasks for writing, summarizing, or translating.
- Stability AI: Use when high-quality image creation from text description is required.
- Meta Llama 2: Perfect for multilingual conversational AI, enabling advanced communication in multiple languages.
2. Most production deployments do not need fine-tuning. They need RAG. Connect a model to your knowledge base, supply the right context at runtime, and you get answers grounded in your business data without retraining anything. Fine-tuning is for the cases where tone, format, or domain language really do need to be baked in.
3. Your application sends prompts and gets back text, images, or embeddings. The same Converse API works across most models, so swapping a model is a configuration change, not a rewrite.
Where Bedrock earns its keep
Bedrock’s unique offering is one of the most fascinating solutions for businesses venturing into generative AI:
- Flexibility: It can address numerous tasks, ranging from customer service chatbots to content creation, which provides flexibility in covering multiple use cases.
- Accessibility: Provides an effortless way to adopt generative AI through accessible pre-trained models that do not require deep technical knowledge to implement.
- Saves Resources: Prototype and deploy applications rapidly, decreasing the time taken to develop and market AI-enabled products and services.
- Cost-Effectiveness: You can save on the training expenses associated with creating an AI by using pre-trained models that take much less time and resources to integrate.
- Scalability: Take advantage of AWS’s strong infrastructure to add capacity based on the demand of the workload.
Use Cases for Amazon Bedrock
Employing the generative solutions of AI is powerful for businesses and an absolutely unique feature of Amazon Bedrock is enabling businesses to leverage that ability. Here are some practical ways it can be applied:
1. Customer Service: With Amazon Bedrock, businesses can create chatbots to provide order updates or assist with troubleshooting common issues. This reduces the workload based on repetitive queries, allowing agents to take on complex tasks and ensuring accurate and timely customer support.
2. Marketing and Content Creation : Bedrock aids marketing professionals with the creation of detailed blog post, and social media posts descriptions, as well as aiding in email creation. Efforts are timed and utilized to ensure effective strategies and innovations are implemented instead of mundane tasks.
3. Product Personalization : With Bedrock businesses can create unique applications resulting in dynamic, AI-enabled product recommendations tailored to individual customer tastes. This improves consumer engagement and repays the business with increased sales, thus enhancing consumers’ overall shopping experience.
4. Analytics and Insights: Bedrock can be used to summarize long analytics processes into short, clear descriptions or focus on identifying specific trends through summarization and executive summary generation. The remaining usable information allows decision-makers to derive correct assumptions and fully use them accurately.
5. Design and Creative Projects : Automated processes in Bedrock support design teams by performing creative functions such as custom image generation and branding asset development. It commences the design process, which allows teams to iterate more effectively while concentrating on creating powerful visuals.
Where AgentCore changes the game
Models on their own are useful but limited. They generate text. They do not call APIs, query a database, remember what happened in last week’s conversation, or coordinate multiple steps to complete a task. That is what an agent does, and that is what AgentCore is built for.
Amazon Bedrock AgentCore became generally available in October 2025, with the Policy and Evaluations services reaching GA in March 2026. AWS reports more than 2 million SDK downloads in the first five months of preview, and customers including PGA TOUR, Epsilon, Ericsson, Thomson Reuters, and Cox Automotive are already running production workloads on the platform. This is not a roadmap announcement. It is a working agent infrastructure.
AgentCore is not one product. It is a set of services that work together or independently with any framework, including open-source options like CrewAI, LangGraph, LlamaIndex, Strands Agents, and Google ADK, and any model in or outside Bedrock.
The Services worth knowing
Every agent task is a loop. The model reasons, decides on an action, takes it, observes the result, and decides what to do next. Five steps in practice:
Managed Agent Orchestration: Consider an agent to be a manager of a project. Once an agent gets a request, the first step is to decompose it into smaller and simpler units. Then, the agent decides in the sequence to perform and execute the units of work. AgentCore, without supervision, solves this reasoning problem and takes over the entire complex workflow.
Multi-Model & Multi-Agent Support: You aren’t locked into a single AI model. AgentCore lets you mix and match various foundational models, such as Claude (Anthropic), Llama (Meta), or Titan (Amazon), all within the same agent. This is beneficial in using the most appropriate model to perform a task, for instance, one model for creative text and another for analysis of the data.
Secure Tool and API Integration: One of the most important features for an agent to be effective is their ability to communicate with other systems. AgentCore enables agents to connect with external APIs, AWS Lambda Functions, and internal databases, creating a safe conduit for agents to leverage existing services as tools.
Memory and Knowledge Integration: With no context, an agent would be ineffective. AgentCore integrates with Amazon Knowledge Bases and allows your agent to access your company’s information. This is done through Retrieval-Augmented Generation. It also has short-term memory to remember the details of the conversation and functions long-term to draw knowledge from past conversations.
Guardrails, Safety, and Governance: Control is very much needed in an enterprise environment. AgentCore has strong governance capabilities and allows for creating rules on what an agent can and cannot do. You can set these rules using free text and make sure your agents work within their safe boundaries and task compliance.
Observability and Monitoring: Once your agent is live, it is essential to understand how it is performing. AgentCore contains performance and issue debugging logs, traces, and metrics. It also has systems for quality assurance of your agent based on various parameters, such as correctness, helpfulness, and safety, to name a few.
How Amazon Bedrock AgentCore Works
Understanding AgentCore systems and processes works best when looking at the workflow of a specific task. The workflow consists of reasoning and action. It is a recursive process.
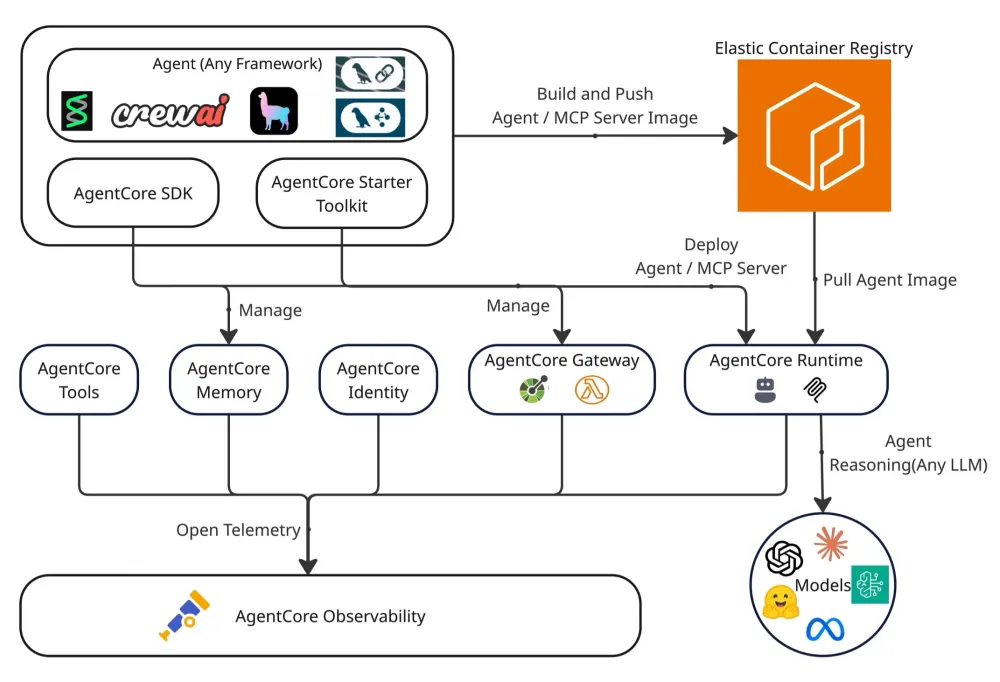
When an agent is assigned a user request, the agent moves through a series of steps coordinated by Bedrock:
- Input and pre-processing. The agent receives the user’s request and adds context (user ID, session history, relevant knowledge).
- Planning. The foundation model breaks the request into steps and decides on a sequence.
- Tool use or knowledge retrieval. The agent calls an API, queries a database, or pulls from a knowledge base, depending on what the step requires.
- Observation and iteration. The agent reads the result, adjusts the plan, and continues until the task is complete.
- Output. The final response is formatted and returned to the user.
A simple example. A customer asks: “check the status of my recent order and send me the tracking link.” The agent plans two steps, calls one API to look up the order, calls a second to fetch the tracking URL, and composes the reply. AgentCore orchestrates that sequence without you writing the orchestration code.
What it actually costs
Bedrock and AgentCore both bill on consumption. There is no minimum commitment and no idle charge for AgentCore Runtime when an agent is waiting on an external API. That matters more than it sounds. Most agent workloads spend the majority of their time idle, waiting on something else.
For AgentCore specifically, here is how the pricing breaks down (current as of mid-2026):
Runtime
CPU: $0.0895 per vCPU-hour, billed only when the agent is actively processing.
Memory: $0.00945 per GB-hour, with a 128 MB minimum.
Gateway
API invocations: $0.005 per 1,000 calls.
Search API: $0.025 per 1,000 calls.
Tool indexing: $0.02 per 100 tools indexed per month.
Memory
Short-term memory: $0.25 per 1,000 events.
Long-term storage: $0.75 per 1,000 events per month.
Retrieval: $0.50 per 1,000 retrievals.
On top of these, you pay for the model inference itself (input and output tokens, per the model you choose) and for any AWS resources your tools consume, such as Lambda or third-party APIs.
Knowledge Retrieval Costs: If your agent has an integration with a knowledge base, Amazon Bedrock RAG retrieval costs apply.
Tool-Related Charges: Costs related to the tools your agent uses, such as AWS Lambda execution, third-party APIs, and others, are charged separately.
A Worked Example
A small internal assistant handling 10,000 monthly requests, 300 input tokens and 200 output tokens per request, using a cost-efficient model:
- Model inference (Nova Micro range): around $0.39 per month.
- Runtime (CPU and memory across 10,000 sessions): around $28.74 per month.
- Gateway invocations: around $0.05 per month.
- Memory events and retrievals: around $6.00 per month.
Total: roughly $35 per month. At this scale, runtime dominates. As you move to higher-tier models or higher-volume workloads, model inference becomes the main cost driver. The 100x price gap between Nova Micro and Claude Opus matters more than any other lever.
How to Keep the bill down
- Right-size the model. Use Nova Micro or smaller Llama variants for classification and routing. Reserve premium models for reasoning and code.
- Engineer prompts properly. Shorter system prompts, summarised memory, and structured outputs reduce token spend significantly.
- Cache aggressively. Bedrock prompt caching can cut costs by up to 90% on repeated inputs. Most teams underuse it.
- Use intelligent prompt routing. Bedrock can automatically route simple queries to smaller models and complex ones to larger models in the same family. AWS reports up to 30% cost reduction without quality loss.
- Batch where you can. Batch inference is 50% cheaper than on-demand for asynchronous workloads.
The Architecture in plain terms
At a high level, AgentCore uses a layered architecture in which each component has a distinct role, allowing organizations to swap or scale individual pieces without rebuilding the entire system. The agent layer runs the core agent logic through AgentCore Runtime, while the reasoning engine relies on foundation models to handle planning and decision-making.
Tool and model routers determine which model or external tool should be called for each task, helping optimize performance and cost. Knowledge and memory layers combine Retrieval-Augmented Generation (RAG) capabilities with both short-term and long-term memory to provide contextual responses.
Finally, AgentCore Gateway enables secure integrations with AWS services and external APIs, allowing agents to interact with enterprise systems and third-party platforms seamlessly.
Where Dedicatted fits
Bedrock and AgentCore lower the barriers, but they do not remove the hard parts. Picking the right model for the workload, designing a knowledge base that retrieves accurately, writing guardrails that hold up under adversarial input, and operating an agent in production while staying within audit and compliance boundaries: those still take experience.
We are an AWS Premier Tier Partner with the Generative AI Competency, MSP designation, and a place in the AWS Agentic AI Pilot program (one of about 60 partners worldwide). We are the only Canadian partner with that combination. We have built and operated agentic systems across financial services, healthcare, manufacturing, and SaaS, and we run them after launch under our MSP practice.
We do not just build it. We run it.
If you are evaluating Bedrock for the first time, or you have a working prototype that needs to graduate into a production-grade, governed deployment, we can help you skip the costly missteps.
Get in touch
Book a working session with our team to map your use case to Bedrock and AgentCore, scope the build, and price it honestly. Talk to us.



