Read summarized version with
Did you know that companies embracing DevOps can deploy software 200x more frequently and recover from failures 24x faster than their competitors? But here’s the catch: while DevOps has become the cornerstone of modern IT, driving speed, agility, and reliability, many organizations stumble along the way. Common DevOps mistakes, like skipping automation, neglecting testing, or overlooking security can quickly derail progress, dilute results, and block you from realizing its full potential.
The truth is, successful DevOps adoption isn’t just about tools – it’s about strategy. Recognizing and fixing these pitfalls early is the difference between a smooth journey and endless roadblocks. That’s where partnering with the right experts comes in.
At Dedicatted , we specialize in helping organizations navigate the complexities of DevOps implementation. As a trusted DevOps services company, our expert guidance ensures you avoid common mistakes while empowering your DevOps Practitioners to embrace best practices and customized strategies that achieve impactful results and foster sustainable growth.
5 Common DevOps Mistakes to Avoid By DevOps Practitioners in 2025
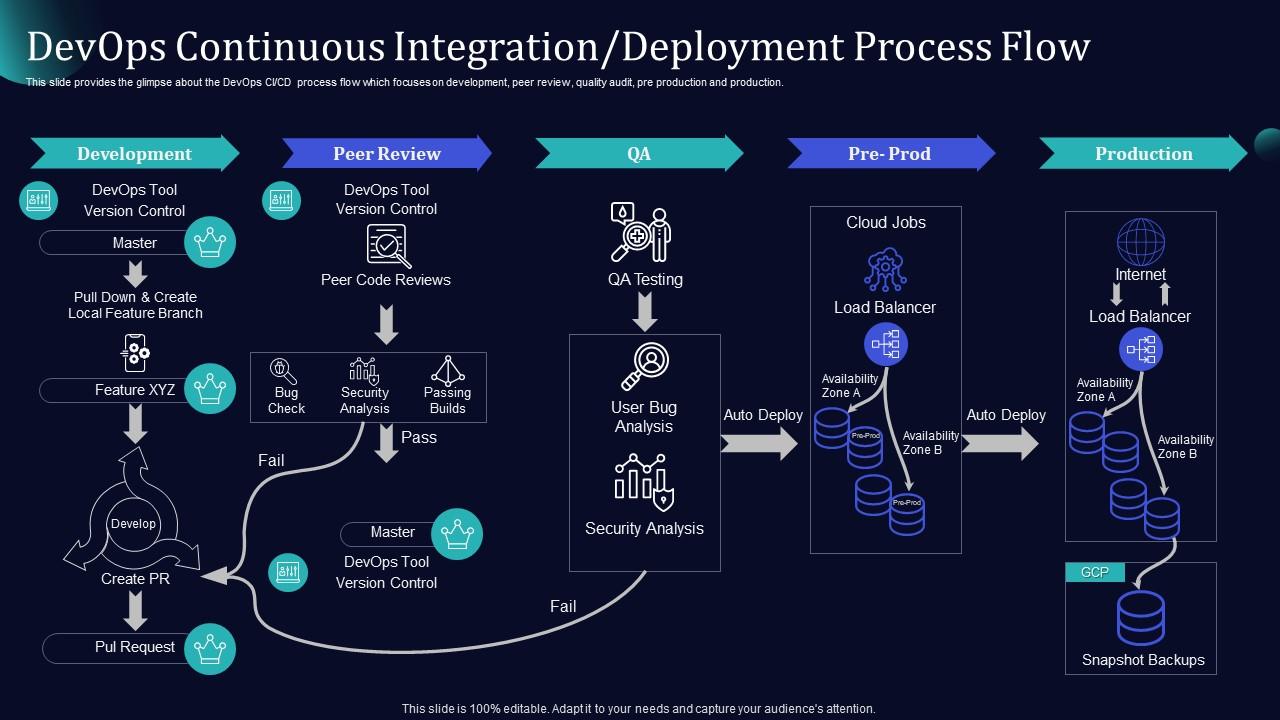
Mistake #1: Misjudging the Finish Line
Many IT and DevOps teams proudly describe their deployment pipeline as a smooth journey: “The application moves from Development, through Test/QA, into Pre-Production, and finally into Production.” But here’s the catch – in over 80% of cases, no one mentions a Post-Production environment.
Why it happens:
Pre-Production is often treated as a sandbox, freely accessible to developers, QA, and anyone who needs to test a change. In practice, this means configurations get tweaked, applications get “fixed” on the fly, and Pre-Production slowly drifts away from being a true mirror of Production. Teams then mistakenly believe they don’t need anything beyond it.
The Impact:
When Pre-Production isn’t a locked-down replica of Production, comparing environments becomes unreliable. That’s when hidden discrepancies, like subtle config differences or untested tweaks creep into Production. The result: Delays, unpredictable failures, and firefighting when systems behave differently in the real world than they did in testing
What Dedicatted Recommends:
Ask yourself: Is Pre-Production truly hands-off? Who has access and are changes strictly controlled? Does it always look identical to Production?
If the answer is “no,” it’s time to introduce a dedicated Post-Production environment.
- Maintain server, middleware, and application configurations consistently across Post-Production and Production
- Automate comparisons to catch discrepancies before they cause failures
- Secure and govern access, ensuring Post-Production remains reliable
With the right approach, Post-Production becomes your safety net, reducing risk and ensuring every deployment lands smoothly in Production.
Mistake #2: Overloading with “Nice-to-Have” Requirements
When choosing tools for a DevOps project, teams often create massive requirement lists – sometimes 10+ pages of spreadsheets with hundreds of line items. While some are essential, many end up being future-oriented “nice-to-haves.” One common example: “The tool must integrate with our CMDB (Configuration Management Database).”
Why it happens
Teams want to “future-proof” their solutions. They think: “We’ll eventually need this, so let’s make sure it’s built-in now.” The problem is, many of these future capabilities like a fully functional CMDB are still years away, or may never materialize. Instead of focusing on immediate goals, the team anchors on features that don’t yet exist.
The Impact:
This mindset makes perfect the enemy of good. By forcing vendors and internal teams to meet requirements that aren’t urgent (or realistic), organizations waste time, inflate costs, and delay releases. Instead of solving today’s problems, DevOps projects get bogged down chasing hypothetical futures
What Dedicatted Recommends:
Don’t build your DevOps strategy around features you might need in three years – focus on what creates value today. Here’s a tangible way to do that/ Prioritize requirements into three buckets:
- Must-have (critical for solving today’s problem)
- Nice-to-have (useful but not urgent)
- Future idea (not actionable yet)
Cut anything in buckets 2 and 3 from your initial tool selection. Keep them documented for future review, but don’t let them slow you down now. Example: Instead of requiring “CMDB integration,” ask: “What information would we want to pull from a CMDB, and do we already store it elsewhere?” If the answer is unclear, drop the requirement.
Count on our experience to deliver a system that works
Mistake #3: Managing “Server #17” Instead of the Application
Too many DevOps teams still think in a server-centric way: monitoring server health, tweaking server configs, and asking “What’s happening with Server #17?” But customers and CIOs don’t care about servers – they care about applications.
No one logs into an ecommerce site and says, “Wow, Server #17 is running great today!” They just want the site to load quickly on Black Friday. Yet many DevOps solutions are still built around managing servers instead of managing the applications those servers power.
Why It Happens:
Historically, applications had a 1:1 relationship with servers, if the server failed, the app failed. It made sense to obsess over server health. But in today’s world of virtualization, cloud, and microservices, one application might run across dozens of physical and virtual servers. Old habits die hard, and teams still default to server-first thinking
The Impact:
This outdated mindset leads to:
- Teams drowning in low-level server monitoring instead of focusing on app performance.
- Slower incident response, since symptoms are tracked per server instead of at the application level.
- A disconnect between IT and business goals – CIOs care about customer experience, not CPU metrics.
In short: managing servers instead of applications keeps DevOps reactive, not strategic.
What Dedicatted Recommends:
Shift the focus from “server health” to application health. That’s where business value lives. Here’s how to make it tangible:
1.Ask application-centric questions:
- Instead of “What’s going on with this server?” → ask “Is the ecommerce app running smoothly across all its servers?”
- Instead of “What are the configs of this server?” → ask “What are the configs of the application across its environment?”
2. Adopt application-first monitoring tools that aggregate server data into application views (APM tools like New Relic, Datadog, or AWS X-Ray).
3. Map dependencies: Identify how critical apps rely on supporting services. This way, if one microservice lags, you see its impact on the whole system – not just on one machine.

Case study
5 min to read
Transforming Platform Reliability and Achieving SOC 2 Compliance for a High-Volume Link Management Service
Mistake #4: The “Two-Pizza Rule” and Death by Meeting
When teams have a lot to accomplish, the instinct is often to get more “hands on deck.” The assumption is: “Together Everyone Achieves More.” But in practice, adding more people to working meetings almost guarantees that nothing meaningful will get done.
If your meeting requires more than two pizzas to feed everyone, Jeff Bezos would say it’s too big. And science backs him up – organizational psychologist Richard Hackman found that communication inefficiencies grow as group size expands. The optimal working meeting size? 5 people – 10 at most. Anything bigger becomes an announcement, not a working session.
Why It Happens:
- Corporate politics: Leaders feel obligated to invite every stakeholder “just in case.”
- Fear of exclusion: Teams don’t want to leave anyone out who might have an opinion.
- Confusion about roles: Without clarity, invitations expand to anyone even loosely connected.
The Impact:
Bloated meetings waste time, dilute accountability, and slow down decisions. Instead of solving problems, teams get stuck in endless discussions where no one owns the outcome. Meanwhile, actual progress is delayed sometimes by weeks.
What Dedicatted Recommends:
First of all apply the Two-Pizza Rule: If your team needs more than two pizzas, your meeting is too big. Limit working meetings to the essential few. Use the R-A-P-I-D framework to decide who belongs in the room:
R – Recommender: The person driving the decision (e.g., Ops Manager).
A – Approver: Only if regulatory or compliance sign-off is needed.
P – Performers: The people who will actually do the work.
I – Influencers: Those with valuable context or expertise.
D – Decider: The ultimate tie-breaker or approver.

Mistake #5: Mixing Legacy Practices with DevOps
Some organizations try to adopt DevOps while still clinging to outdated tools, manual processes, or siloed workflows. This creates a “hybrid DevOps” approach that may feel safer during the transition – but in reality, it slows everything down and leaves teams stuck halfway between old and new.
Why It Happens:
- Resistance to change: Teams are comfortable with legacy tools they’ve used for years and hesitate to switch.
- Budget limits: Leadership may delay investments in modern infrastructure, hoping to “make do” with what’s already in place.
- Fear of disruption: Organizations worry that changing too much too quickly will break existing systems.
The Impact:
This hybrid approach undermines everything DevOps is supposed to deliver:
- Slower workflows because old manual steps remain in place.
- Inconsistency between teams using modern CI/CD pipelines and those stuck with legacy tools.
- Missed opportunities for innovation, automation, and faster delivery.
Instead of reaping DevOps benefits like agility and reliability, companies end up with extra complexity and frustrated teams.
What Dedicatted Recommends:
A successful DevOps journey requires going all in, but that doesn’t mean tearing everything down overnight. Here’s a practical way forward:
Audit your toolchain: Identify where legacy tools create bottlenecks. For example, is manual deployment still slowing releases even though CI/CD is in place?
Prioritize modernization by impact: Start replacing the tools or processes that block automation first. Don’t waste energy modernizing systems that don’t affect delivery.
Upskill teams gradually: Provide training so people understand not just how to use DevOps tools, but why they matter.
Bridge, then replace: If a legacy system must stay for now, ensure it integrates cleanly with DevOps workflows – then set a clear timeline to phase it out.
Case study: Enabling Security Compliance and DevOps Agility in a Regulated Healthcare Environment
Many healthcare organizations struggle with the complexities of DevOps adoption, particularly when operating under strict compliance requirements. Challenges such as siloed teams, manual workflows, and limited automation often slow innovation and increase operational risk.
A leading healthcare provider chose to partner with Dedicatted, leveraging our expertise in DevOps strategy for regulated environments. This collaboration proved transformative, enabling the client to overcome common DevOps pitfalls while ensuring security and regulatory compliance.
The results were immediate and impactful:
- Seamless Cloud Transition: The client successfully migrated to Azure with zero user disruption, ensuring continuous service for thousands of active users.
- Enhanced Compliance: Security controls and infrastructure policies were fully aligned with high-trust compliance standards, satisfying internal audits and regulatory requirements.
- HIPAA Assurance: Full coverage of technical HIPAA controls provided peace of mind and a clear roadmap for future audits and certifications
Want the full story? Read the full case study: Enabling Security Compliance and DevOps Agility in a Regulated Healthcare Environment


