Read summarized version with
Generative AI may be stealing the spotlight – but behind every production-grade AI experience lies an unsung hero: LLMOps.If your organization is struggling to scale LLMs beyond the prototype phase, you’re not alone
Struggling to bring LLMs into production? Dedicatted helps data-driven companies build, operate, and scale GenAI systems that perform – securely and efficiently. Book a free LLMOps discovery session
In fact, over 80% of AI projects never make it into production – a staggering statistic that reveals a harsh truth: deploying LLMs is easy; operating them effectively is not. That’s where Large Language Model Operations, or LLMOps, comes in. It’s the secret sauce that transforms experimental models into reliable business tools.
In this article, we’ll break down what LLMOps actually is, how it differs from MLOps, and why it’s quickly becoming a non-negotiable for enterprises aiming to compete in the AI economy. Ready to stop experimenting and start scaling? Let’s crack LLMOps together.
Large Language Model Operations: The Key to Managing Large Language
Deploying large language models (LLMs) goes far beyond building flashy prototypes. While LLMs offer rapid experimentation and plug-and-play functionality that can generate impressive results in minutes, turning that prototype into a production-ready, scalable solution is a whole different challenge. From sourcing clean, domain-specific data to crafting effective prompts, fine-tuning models, and ensuring real-time responsiveness – every step introduces complexity. Most importantly, LLMs are not static systems; they require continuous updates and refinements as user behavior shifts and data evolves.
That’s where LLMOps becomes indispensable. You’re not just deploying a model – you’re setting up an evolving AI capability that demands frequent iteration, monitoring, and compliance. Unlike traditional software or even classical machine learning systems, managing LLMs calls for new thinking around deployment pipelines, versioning, and user feedback loops.
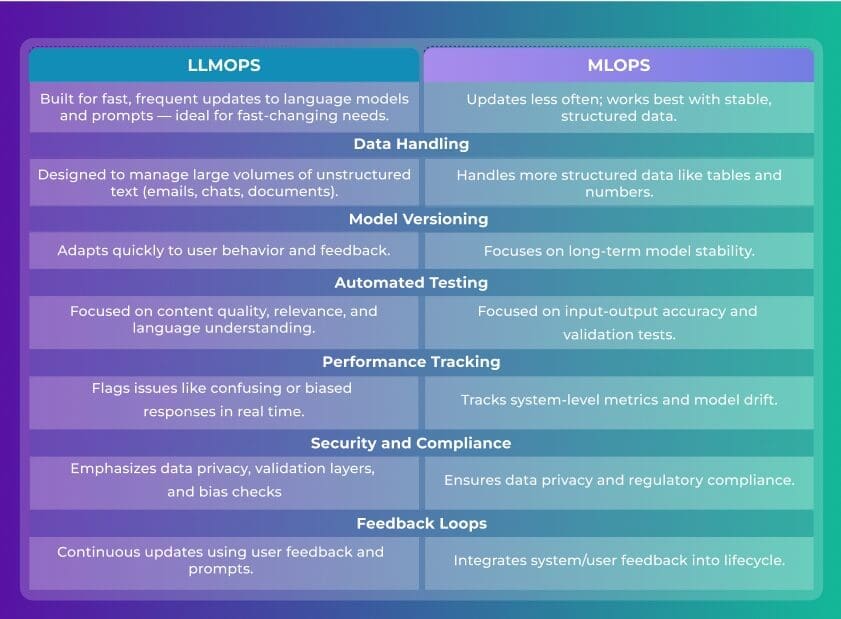
Below we break down how LLMOps compares with MLOps, showing how each supports different AI operational needs and where LLMOps steps in to handle the demands of modern, generative language applications.
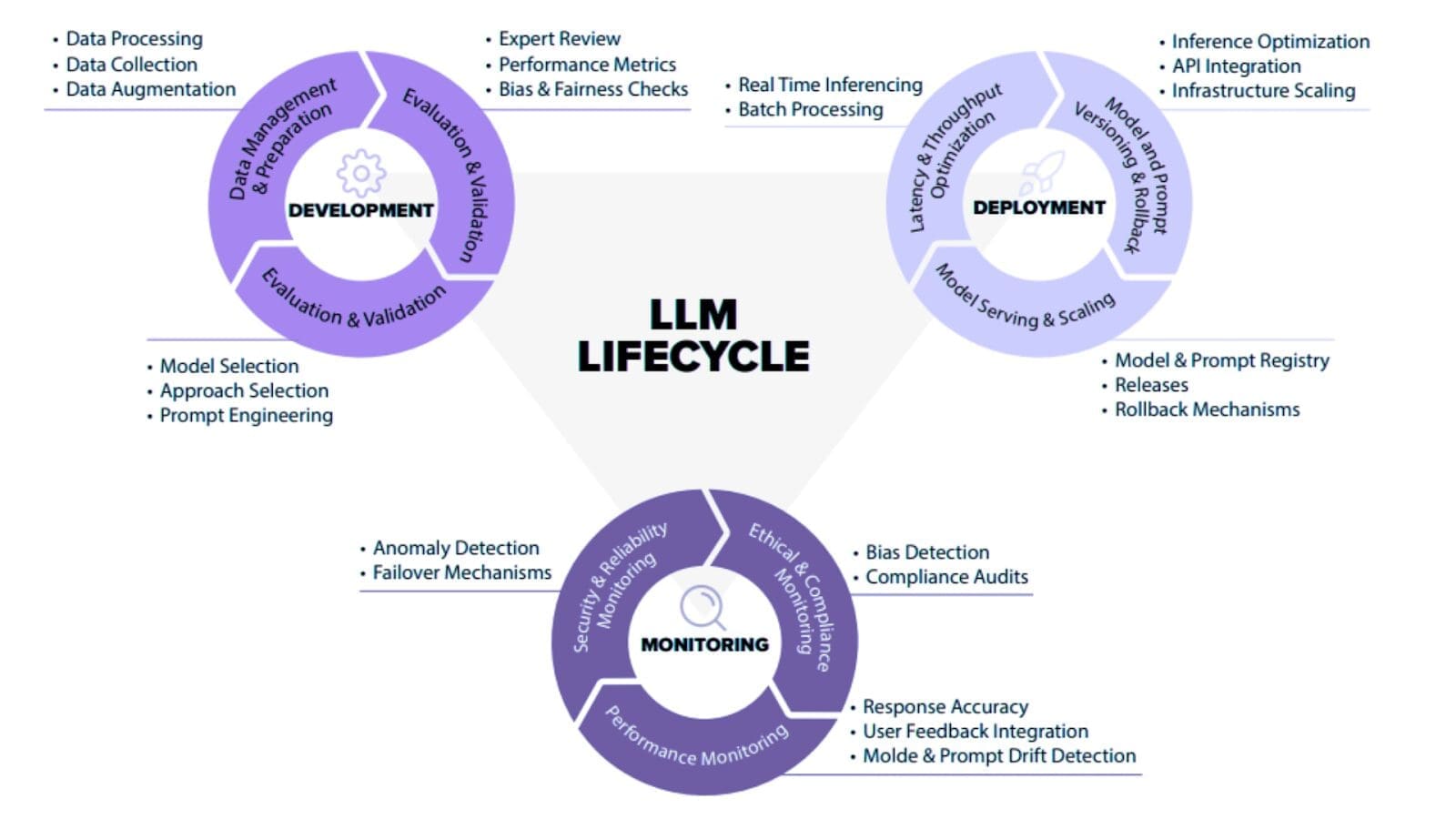
Mastering the LLM Lifecycle: The Crucial Role of LLMOps
Large Language Models (LLMs) bring massive potential – but managing them in production is no small feat. As these models evolve, ensuring they remain reliable, scalable, and aligned with business goals becomes increasingly complex. Think of it as the engine room of your generative AI efforts, quietly powering everything behind the scenes to make sure your model doesn’t just run – it thrives.
1. Deployment Done Right. LLM versions evolve rapidly – with changing APIs, configurations, and behaviors. A careless rollout can break downstream applications or introduce bias.
At Dedicatted, our LLMOps engineers design battle-tested deployment pipelines with automated versioning, rollback control, and compliance auditing – ensuring every model update is safe, fast, and traceable. This is how we help teams release weekly without fear of breaking production.

Case study
5 min to read
Automating remittance workflows and reducing costs with GenAI and AWS
2. Real-Time Monitoring at Scale. Once the model is live, the real work begins. LLMs can react unpredictably to shifts in input data or user behavior.
We are leaning towards integrating real-time monitoring tools to catch anomalies early – tracking performance, surfacing drift, and alerting teams when things veer off course. From dashboards to A/B testing and anomaly detection, monitoring isn’t an afterthought – it’s a continuous discipline.
3. Continuous Maintenance & Retraining
Over time, even top-performing models degrade. Data drifts, user needs change, and underlying infrastructure evolves.
Our recommendation: try maintaining a transparent record of datasets, code, hyperparameters, and performance metrics, this gives opportunity for teams to retrain and refine models with confidence – preserving quality while adapting to change.
4. Building the Foundations for GenAI Success
Implementing LLMOps isn’t plug-and-play. It starts with assessing your organization’s readiness – do you have the infrastructure, data governance, and team skills in place?
From here, Dedicatted takes the lead – covering everything from data collection and preprocessing, to inference optimization, prompt engineering, and version management.

5. Governance, Automation, and Adaptability
LLMOps is more than operations – it’s about establishing governance, automation, and adaptability in the age of intelligent systems. That includes:
- Scalable infrastructure with auto-scaling and low-latency support
- Prompt and model registries with rollback capabilities
- Evaluation pipelines with fairness, bias detection, and expert review
- Strategies like RAG (retrieval-augmented generation) or agent-based approaches for cutting-edge performance
For insurers like Xodus, GenAI automation had to meet strict compliance standards. We delivered a claims system with versioned prompts, bias checks, and full traceability – LLMOps built for real-world accountability: Read the full story
Production-Ready LLMs? We Make It Happen on AWS
When it comes to building scalable, secure, and high-performing LLMOps infrastructure, AWS sets the gold standard. With over 70% of GenAI workloads running on AWS, it’s the go-to ecosystem for enterprises.
But AWS gives you the tools – not the blueprint. That’s where Dedicatted comes in. We applied LLMOps principles to help Xodus, a travel insurance provider, streamline claims processing. By integrating GenAI into their adjudication workflow on AWS, we cut manual document handling by 70%, dramatically reducing labor and accelerating throughput.
Want to explore what LLMOps on AWS could look like for your business?
Built for AWS, Tailored to You
We work natively within the AWS ecosystem – using SageMaker, Lambda, Step Functions, EKS, and more – to create automated pipelines that fit your unique setup. No bloated solutions, no extra complexity. Just scalable, secure, and clean architecture that supports your team’s speed and flexibility.
Full Visibility, Right from the Start
LLMs evolve fast – and so should your observability. We bake in real-time monitoring from day one using AWS-native tools like CloudWatch and SageMaker Model Monitor, and extend it with WhyLabs or Arize AI when needed. You’ll always know how your models are performing, where drift is creeping in, or when retraining is needed – before it affects results.
Faster Updates, Less Risk
When you’re ready to ship updates, we make sure you can do it without second-guessing. With CI/CD pipelines designed specifically for model workflows, canary deployments, rollback paths, and version tracking, you can experiment and improve continuously – without putting production at risk.
Smart Management of Models and Prompts
We help you stay in control of every iteration. From prompt tuning to full model versioning, we set up registries and testing workflows that let you compare, track, and revert easily. With SageMaker endpoints and real-time A/B testing, it’s easy to scale what works – and drop what doesn’t.
Speed That Doesn’t Break the Bank
LLMs can be resource-heavy – but they don’t have to be expensive. We tune performance using techniques like model compression, optimized inference with AWS Inferentia, and intelligent scaling strategies that align with your actual usage – not your worst-case scenario.



